从现在开始,我们就来分析Python中常见的内置对象、以及对应的实例对象,看看它们在底层是如何实现的。但说实话,我们在前面几节中介绍对象的时候,已经说了不少了,不过从现在开始要进行更深入的分析。
Tags:
via Pocket https://ift.tt/3jTOtRj original site
February 16, 2021 at 10:08PM
Comments
from: github-actions[bot] on: 3/8/2021
《深度剖析CPython解释器》4. 解密Python中最简单的对象–浮点数的底层实现 - 古明地盆 - 博客园
《深度剖析CPython解释器》4. 解密Python中最简单的对象–浮点数的底层实现
楔子
从现在开始,我们就来分析Python中常见的内置对象、以及对应的实例对象,看看它们在底层是如何实现的。但说实话,我们在前面几节中介绍对象的时候,已经说了不少了,不过从现在开始要进行更深入的分析。
除了对象本身,还要看对象支持的操作在底层是如何实现的。我们首先以浮点数为例,因为它是最简单的,没错,浮点数比整型要简单。至于为什么,当我们分析整型的时候就知道了。
内部对象
float实例对象定义在Include/floatobject.h中,结构非常简单:
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;除了PyObject这个公共的头部信息之外,只有一个额外的ob_fval,用于存储具体的值,而且直接使用的C中的double。

那么float类型对象在底层长啥样子呢?
与实例对象不同,float类型对象全局唯一,因此可以作为全局变量定义。底层对应PyFloat_Type,位于Objects/typeobject.c中。
PyTypeObject PyFloat_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"float",
sizeof(PyFloatObject),
0,
(destructor)float_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
(reprfunc)float_repr, /* tp_repr */
&float_as_number, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
(hashfunc)float_hash, /* tp_hash */
0, /* tp_call */
(reprfunc)float_repr, /* tp_str */
PyObject_GenericGetAttr, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, /* tp_flags */
float_new__doc__, /* tp_doc */
0, /* tp_traverse */
0, /* tp_clear */
float_richcompare, /* tp_richcompare */
0, /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
float_methods, /* tp_methods */
0, /* tp_members */
float_getset, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
0, /* tp_dictoffset */
0, /* tp_init */
0, /* tp_alloc */
float_new, /* tp_new */
};PyFloat_Type中保存了很多关于浮点数对象的元信息,关键字段包括:
tp_name字段保存了类型名称,是一个char *,显然是"float";tp_dealloc、tp_init、tp_alloc和 tp_new字段是与对象创建销毁相关的函数;tp_repr字段对应__repr__方法,生成语法字符串;tp_str字段对应__str__方法,生成普通字符串;tp_as_number字段对应数值对象支持的操作簇;tp_hash字段是哈希值生成函数;
PyFloat_Type很重要,作为浮点类型对象,它决定了浮点数的生死和行为。
对象的创建
在上一篇博客中,我们初步了解到创建实例对象的一般过程。对于内置类型的实例对象,可以使用Python/C API创建,也可以通过调用类型对象创建。
调用类型对象float创建实例对象,Python执行的是type类型对象中的tp_call函数。tp_call中会先调用类型对象的tp_new为该对象的实例对象申请一份空间,申请完毕之后该对象就已经被创建了。然后会再调用tp_init,并将实例对象作为参数传递进去,进行初始化,也就是设置属性。
但是对于float来说,它内部的tp_init成员是0,从PyFloat_Type的定义我们也可以看到。说明float没有__init__函数,原因是float是一种很简单的类型对象,初始化操作只需要一个赋值语句,所以在tp_new中就可以完成。
除了通过调用类型对象创建实例对象这种通用型方法之外,CPython还为内置类型对象提供了一些Python/C API来创建对应的实例对象。可以简化调用,提高效率。关于为什么可以提高效率,我们之前已经分析过了,我们说通过Python/C API创建的话,会直接解析成底层对应的数据结构,而通过类型对象调用的话则会有一些额外的开销。
PyObject *
PyFloat_FromDouble(double fval);
PyObject *
PyFloat_FromString(PyObject *v);以上是底层提供的两个创建浮点数的C API,当然还有其它的。
PyFloat_FromDouble:通过C中的double创建float对象;PyFloat_FromString:通过字符串对象创建float对象;
以PyFloat_FromDouble为例,我们看看底层是怎么创建的?该函数同样位于Objects/floatobject.c中。
PyObject *
PyFloat_FromDouble(double fval)
{
//我们之前在介绍引用计数的时候,说过引用计数为0了,那么对象会被销毁
//但是对象所占的内存则不一定回收、或者说还给操作系统,而是会缓存起来
//所以从这行代码我们就看到了,创建浮点数对象的时候会优先从缓存池里面获取
//而缓存池是使用链表实现的,free_list(指针)指向的链表的第一个对象
PyFloatObject *op = free_list;
//op不是NULL,说明缓存池中有对象,成功获取
if (op != NULL) {
//一旦获取了,那么要将free_list指向链表中当前获取的对象的下一个对象
//但是Py_TYPE不是一个宏吗?它获取的应该是对象的ob_type啊,那么Py_TYPE(op)获取的不是PyFloat_Type指针吗?别急这一点我们后面会说
free_list = (PyFloatObject *) Py_TYPE(op);
//并且将缓存池的内部可以使用的浮点数对象的数量减1
//关于缓存池, 以及为什么要使用缓存池下面也会细说
//目前先知道Python在分配浮点数对象的时候会先从缓存池里面获取就可以了
numfree--;
} else {
//否则的话,调用PyObject_MALLOC申请内存,PyObject_MALLOC是基于malloc的一个封装
op = (PyFloatObject*) PyObject_MALLOC(sizeof(PyFloatObject));
//申请失败的话,证明内存不够了
if (!op)
return PyErr_NoMemory();
}
//走到这里说明内存分配好了,PyFloatObject也创建了,但是不是还少了点啥呢?显然内部的成员还没有初始化
//还是那句话内置类型的实例对象该分配多少空间,解释器了如指掌,因为通过PyFloatObject内部的成员一算就出来了。
//因此虽然对象创建了,但是此时内部的ob_refcnt、ob_type、以及ob_fval三个成员还没有被初始化。
//所以还要将其ob_refcnt设置为1(因为对于刚创建的对象来说,内部的引用计数显然为1),将ob_type设置为指向PyFloat_Type的指针
//而PyObject_INIT是一个宏,它就是专门用来设置ob_type以及ob_refcnt的,我们后面看这个宏的定义就知道了
(void)PyObject_INIT(op, &PyFloat_Type);
//将内部的ob_fval成员设置为fval,所以此时三个成员都已经初始化完毕
op->ob_fval = fval;
//将其转成PyObject *返回
return (PyObject *) op;
}所以整体流程如下:
1. 为实例对象分配内存空间,空间分配完了对象也就创建了,不过会优先使用缓存池;2. 初始化实例对象内部的引用计数和类型指针;3. 初始化ob_fval为指定的浮点值;
然后我们看一下PyObject_INIT这个宏,它位于Include/objimpl.h中。
#define PyObject_INIT(op, typeobj) \
( Py_TYPE(op) = (typeobj), _Py_NewReference((PyObject *)(op)), (op) )
//这个宏接收两个参数,分别是:实例对象的指针和指向的类型对象的指针
//然后Py_TYPE(op)表示获取其内部的ob_type, 将其设置为typeobj, 而typeobj在源码中传入的就是&PyFloat_Type
//然后是_Py_NewReference, 这个宏我们在上一篇博客中已经说过了,它用于将对象的引用计数初始化为1对象的销毁
当删除一个变量时,Python会通过宏Py_DECREF或者Py_XDECREF来减少该变量指向的对象的引用计数;当引用计数为0时,就会回收该对象。而回收该对象会调用其类型对象中的tp_dealloc指向的函数。当然啦,CPython依旧为回收对象提供了一个宏,我们上一篇中也说过了。
#define _Py_Dealloc(op) ( \
_Py_INC_TPFREES(op) _Py_COUNT_ALLOCS_COMMA \
(*Py_TYPE(op)->tp_dealloc)((PyObject *)(op)))
// _Py_Dealloc(op)会调用op指向的对象的类型对象中的析构函数,同时将op自身作为参数传递进去,表示将op指向的对象回收。而PyFloat_Type中的tp_dealloc成员被初始化为float_dealloc,所以析构函数最终执行的是float_dealloc,关于它的源代码我们会在一会儿介绍缓存池的时候细说。
总结一下的话,浮点数对象从创建到销毁整个生命周期所涉及的关键函数、宏、调用关系可以如下图所示:

我们看到通过类型对象调用的方式来创建实例对象,最终也是要走Python/C API的,肯定没有直接通过Python/C API创建的方式快,因为前者多了几个步骤。
所以如果是float(3.14),那么最终也会调用PyFloat_FromDouble(3.14);如果是float(“3.14”),那么最终会调用PyFloat_FromString(“3.14”)。所以调用类型对象的时候,会先兜个圈子再去使用Python/C API,肯定没有直接使用Python/C API的效率高。
缓存池
我们说浮点数这种对象是经常容易被创建和销毁的,如果每创建一个就分配一次内存、每销毁一个就回收一次内存的话,那效率会低到可想而知了。我们知道Python在操作系统之上封装了一个内存池,可以用于小内存对象的快速创建和销毁,这便是Python的内存池机制。但浮点数使用的频率很高,我们有时会创建和销毁大量的临时对象,所以如果每一次对象的创建和销毁都伴随着内存相关的操作的话,这个时候即便是有内存池机制,效率也是不高的。
考虑如下代码:
>>> pi = 3.14
>>> r = 2.0
>>> s = pi * r ** 2
>>> s
12.56
>>>这个语句首先计算半径r的平方,然后根据结果创建一个临时对象,假设是t;然后再将pi和t进行相乘,得到最终结果并赋值给s;最终销毁临时变量t,所以这背后是隐藏着一个临时对象的创建和删除的。
当然这里一行代码可能感觉不到啥,假设我们要计算很多很多个半径对应的面积呢?显然需要写for循环,如果循环一万次就意味着要创建和销毁临时对象各一万次。
因此,如果每一次创建对象都需要分配内存,销毁对象时需要回收内存的话,那么大量临时对象的创建和销毁就意味着要伴随大量的**内存分配以及回收操作**,这显然是无法忍受的,更何况Python的for循环本身就已经够慢了。
因此Python在浮点数对象被销毁后,并不急着回收对象所占用的内存,换句话说其实对象还在,只是将该对象放入一个空闲的链表中。因为我们说对象可以理解为就是一片内存空间,对象如果被销毁,那么理论上内存空间要归还给操作系统,或者回到内存池中;但Python考虑到效率,并没有真正的销毁对象,而是将对象放入到链表中,占用的内存还在;后续如果再需要创建新的浮点数对象时,那么从链表中直接取出之前放入的对象(我们认为被回收的对象),根据新的浮点数对象重新初始化对应的成员即可,这样就避免了内存分配造成的开销。而这个链表就是我们说的缓存池,当然不光浮点数对象有缓存池,Python中的很多其它对象也有对应的缓存池,比如列表。
浮点对象的空闲链表同样在 Objects/floatobject.c中定义:
#ifndef PyFloat_MAXFREELIST
#define PyFloat_MAXFREELIST 100
#endif
static int numfree = 0;
static PyFloatObject *free_list = NULL;PyFloat_MAXFREELIST:缓存池中能容纳float实例对象的最大数量, 显然不可能将所有要销毁的对象都放入到缓存池中, 这里是100个;numfree:表示当前缓存池(链表)中的已经存在的float实例对象的数量, 初始为0;free_list: 指向链表头结点的指针, 链表里面存储的都是PyFloatObject, 所以头节点的指针就是PyFloatObject *
但是问题来了,如果是通过链表来存储的话,那么对象肯定要有一个指针,来指向下一个对象,但是浮点数对象内部似乎没有这样的指针啊。是的,因为Python是使用内部的ob_type来指向下一个对象,本来ob_type指向的应该是PyFloat_Type,但是在链表中指向的是下一个PyFloatObject。
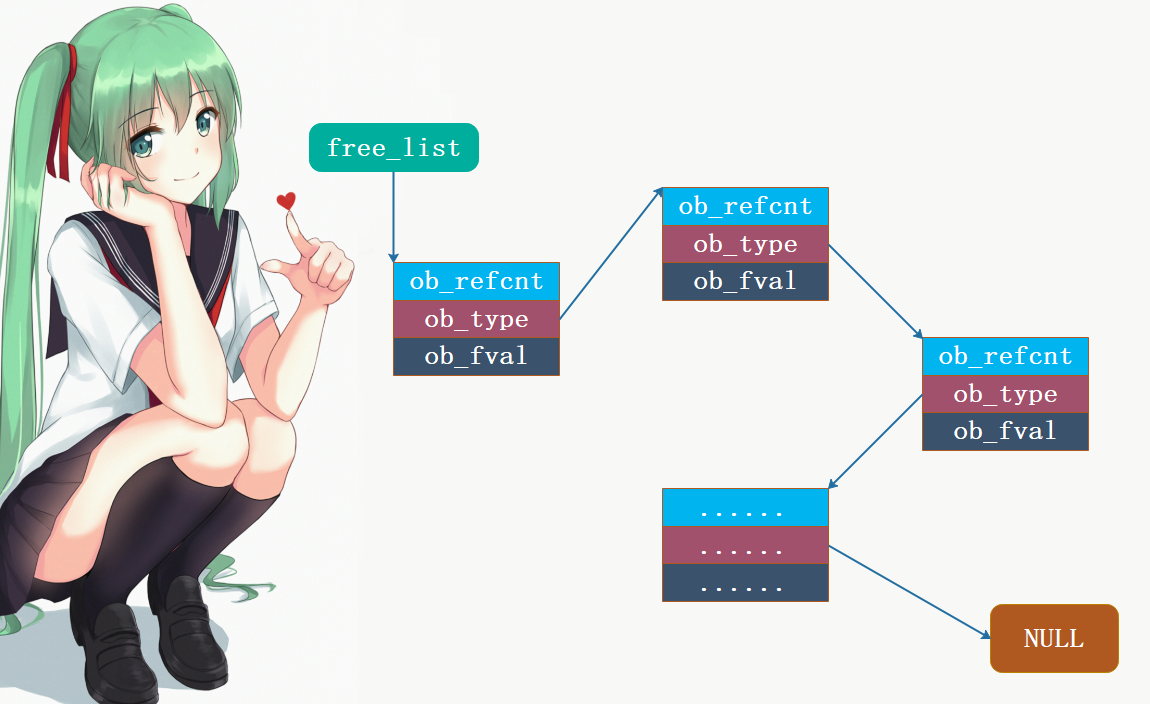
所以我们再回过头来看看PyFloat_FromDouble:
PyObject *
PyFloat_FromDouble(double fval)
{
//显然op是缓存池中第一个PyFloatObject的指针
PyFloatObject *op = free_list;
if (op != NULL) {
// 这个时候链表中的第一个对象已经被取出来重新分配了,显然free_list要指向下一个PyFloatObject
//我们说在链表中,ob_type被用于指向链表中的下一个PyFloatObject,换言之ob_type保存的是下一个PyFloatObject的地址
//但ob_type虽然保存的是PyFloatObject的地址,但它的类型仍是struct _typeobject *, 或者说PyTypeObject *
//所以在存储的时候,下一个PyFloatObject *一定是先转成了struct _typeobject *之后,再交给的ob_type,因为对于指针来说,是可以任意转化的
//所以Py_TYPE(op)获取下一个对象的指针之后,还要再转成PyFloatObject *,然后交给free_list保存
//如果没有下一个对象了,那么free_list就是NULL
//因此在下一次分配的时候,上面if (op != NULL)就不成立了,因此会走下面的else,使用PyObject_MALLOC重新分配内存
free_list = (PyFloatObject *) Py_TYPE(op);
numfree--;
} else {
op = (PyFloatObject*) PyObject_MALLOC(sizeof(PyFloatObject));
if (!op)
return PyErr_NoMemory();
}
//.......
return (PyObject *) op;
}我们说对象创建时,会先从缓存池中获取。既然创建时可以从缓存池获取,那么销毁的时候,肯定要放入到缓存池中。而销毁对象会调用类型对象的析构函数tp_dealloc,对于浮点数而言就是float_dealloc,我们看一下源代码,同样位于Objects/floatobject.c中。
static void
float_dealloc(PyFloatObject *op)
{
if (PyFloat_CheckExact(op)) {
//如果numfree(当前缓存池中float实例对象的数量)达到了缓存池的最大容量
if (numfree >= PyFloat_MAXFREELIST) {
//那么调用PyObject_FREE回收对象所占内存
PyObject_FREE(op);
return;
}
//否则的话,说明没有达到最大容量限制,显然此时不会真的销毁对象,而是将其放入缓存池中
//将numfree加1
numfree++;
//我们说free_list指向链表的第一个元素,而这里是获取了op的ob_type,让其等于free_list,说明该对象内部的ob_type也指向了链表中的第一个元素
//那么说明了什么,是不是意味着链表中第一个元素就变成该对象了。因此在将对象放入链表中的时候,是放在链表的头部位置
//但我们说ob_type的类型是struct _typeobject *,所以还要将free_list进行转化
//那么显然在获取的时候,还要再转成PyFloatObject *,这在上面的PyFloat_FromDouble中我们已经看到了
Py_TYPE(op) = (struct _typeobject *)free_list;
//我们说free_list指向链表中的第一个元素,但现在第一个元素变了
//所以要让free_list = op, 指向新添加的PyFloatObject,因为它被插入到了链表的第一个位置上
free_list = op;
}
//否则的话,说明PyFloat_CheckExact(op)为假, PyFloat_CheckExact(op)是用于检测op是不是指向PyFloatObject
//说明此时op可能指向的其实不是PyFloatObject *,所以通过Py_TYPE(op)->tp_free直接获取对应的类型对象的tp_free,然后释放掉op指向的对象所占的内存。
else
Py_TYPE(op)->tp_free((PyObject *)op);
}这便是Python的浮点数对象(或者浮点数空闲对象)缓存池的全部秘密,由于对象缓存池在提高对象分配效率方面发挥着至关重要的作用,所以Python中很多其它内置对象的实例对象也都实现了缓存池,我们后续在分析其它对象的时候会经常看到它的身影。
看一个思考题:
>>> a = 1.414
>>> id(a)
2431274355248
>>>
>>> del a
>>>
>>> b = 1.732
>>> id(b)
2431274355248
>>>我们看到两个对象的id是一样的,相信你肯定知道原因。因为a在del之后,指向对象被放入到缓存池中,然后创建b的时候会从缓存池中获取,所以a指向的对象被重新利用了,内存还是原来的那一块内存,所以前后地址没有变化。
对象的行为
PyFloat_Type中定义了很多的函数指针,比如:type_repr、tp_str、tp_hash等等,这些函数指针将一起决定float实例对象的行为,例如:tp_hash决定float实例对象的哈希值是如何计算的:
>>> e = 2.71
>>> hash(e)
1637148536541722626
>>>tp_hash指向的是float_hash,还是那句话Python底层的函数命名以及API都是很有规律的,相信你能慢慢发现。
static Py_hash_t
float_hash(PyFloatObject *v)
{
//我们看到调用了_Py_HashDouble,计算的就是ob_fval成员哈希值
return _Py_HashDouble(v->ob_fval);
}由于加减乘除等数值操作很常见, Python 将其抽象成数值操作簇 PyNumberMethods,并让内部成员tp_as_number指向。数值操作集 PyNumberMethods 在头文件 Include/object.h 中定义:
typedef struct {
/* Number implementations must check *both*
arguments for proper type and implement the necessary conversions
in the slot functions themselves. */
binaryfunc nb_add;
binaryfunc nb_subtract;
binaryfunc nb_multiply;
binaryfunc nb_remainder;
binaryfunc nb_divmod;
ternaryfunc nb_power;
unaryfunc nb_negative;
// ...
binaryfunc nb_inplace_add;
binaryfunc nb_inplace_subtract;
binaryfunc nb_inplace_multiply;
binaryfunc nb_inplace_remainder;
ternaryfunc nb_inplace_power;
//...
} PyNumberMethods;PyNumberMethods定义了各种数学算子的处理函数,数值计算最终由这些函数执行。 处理函数根据参数个数可以分为: 一元函数(unaryfunc) 、 二元函数(binaryfunc) 和 三元函数(ternaryfunc )。
然后我们回到Objects/floatobject.c中观察一下PyFloat_Type是如何初始化的。
static PyNumberMethods float_as_number = {
float_add, /* nb_add */
float_sub, /* nb_subtract */
float_mul, /* nb_multiply */
float_rem, /* nb_remainder */
float_divmod, /* nb_divmod */
float_pow, /* nb_power */
(unaryfunc)float_neg, /* nb_negative */
// ...
0, /* nb_inplace_add */
0, /* nb_inplace_subtract */
0, /* nb_inplace_multiply */
0, /* nb_inplace_remainder */
0, /* nb_inplace_power */
// ...
};以加法为例,显然最终执行float_add,源码位于Objects/floatobject.c中,显然它是一个二元函数。
static PyObject *
float_add(PyObject *v, PyObject *w)
{
//显然两个Python对象相加,一定是先将其转成C的对象相加,加完之后再根据结果创建新的Python对象
//所以声明了两个double
double a,b;
//CONVERT_TO_DOUBLE是一个宏,不用想,功能肯定是将PyFloatObject里面的ob_fval抽出来给double变量,从名字上也能看出来
//这个宏有兴趣可以去源码中看一下,也在当前文件中
CONVERT_TO_DOUBLE(v, a); // 将ob_fval赋值给a
CONVERT_TO_DOUBLE(w, b); // 将ob_fval赋值给b
//PyFPE_START_PROTECT和下面的PyFPE_END_PROTECT也都是宏,作用我们一会儿说。
PyFPE_START_PROTECT("add", return 0)
//将a和b相加赋值给a
a = a + b;
PyFPE_END_PROTECT(a)
//根据相加后的结果创建新的PyFloatObject对象,当然返回的是泛型指针PyObject *
return PyFloat_FromDouble(a);
}所以以上就是float实例对象的运算,核心就是:
1. 定义两个double变量:a、b2. 将用来相加的两个float实例对象中ob_fval维护的值抽出来赋值给a和b3. 让a和b相加,将相加结果传入PyFloat_FromDouble中创建新的PyFloatObject,然后返回其PyObject *
所以如果是C中的两个浮点数相加,直接a + b就可以了,编译之后就是一条简单的机器指令,然而Python则需要额外做很多其它工作。并且在介绍整型的时候,你会发现Python中的整型的相加会更麻烦,但对于C而言同样是一条简单的机器码就可以搞定。当然啦,因为Python3中的整型是不会溢出的,所以需要额外的一些处理,等介绍整型的时候再说吧。所以这里我们也知道Python为什么会比C慢几十倍了,从一个简单的加法上面就可以看出来。
最后我们再说一下PyFPE_START_PROTECT和PyFPE_END_PROTECT这两个宏,其实它们对于我们了解浮点数在底层的计算没有什么意义。首先浮点数计算一般都遵循IEEE-754标准,如果计算时出现了错误,那么需要将IEEE-754异常转换成Python中的异常,而这两个宏就是用来干这件事情的。
所以我们不需要管它,这两个宏定义在Include/pyfpe.h中,并且Python3.9的时候会被删除掉。
最后我们说一下Python解释器源代码的结构吧,因为我们每一次介绍函数的时候,都会说该函数定义在哪个文件里。所以突然想起来,介绍一下源代码的组织结构也是有必要的。
我们从官网上将源代码下载下来之后,大概长这样,里面有几个目录是我们需要关注的。
Include:该目录包含了Python所提供的所有头文件,主要包含了一些实例对象在底层的定义,比如listobject.h、dictobject.h等等。如果用户需要自己使用C或者C++来编写自定义模块扩展Python,那么也需要用到这里的头文件。Lib:这个无需多说,该目录包含了python自带的所有标准库,Lib中的库基本上都是使用python编写的。Modules:该目录中包含了所有用C语言编写的模块,比如_random、_io等,而且gc也在里面。Modules中的模块是那些对速度要求非常严格的模块,而有一些对速度没有太严格要求的模块,比如os,就是用Python编写,并且是放在Lib目录下的。Parser:该目录中包含了python解释器中的Scanner和Parser部分,即对python源代码进行词法分析和语法分析的部分。除了这些,Parser还包含了一些有用的工具,这些工具能够根据Python语言的语法自动生成Python语言的词法和语法分析器,与YACC非常类似。Objects:该目录包含了所有Python的内置类型对象的实现,以及其实例对象相关操作的实现,比如浮点数相关操作就位于文件floatobject.c中、列表相关操作就位于文件listobject.c中,文件名也很有规律。同时,该目录还包含了Python在运行时需要的所有内部使用对象的实现,因为有很多对象比如<class 'function'>是没有暴露给Python的,但是在底层它们是实现了的。Python:虚拟机的实现相关,是python运行的核心所在。
PyFloatObjectに侵入し
最后我们修改一下源码:当对象放入到缓冲池中,我们打印一下放入的浮点数对象的地址;当对象从缓存池中取出时,我们打印一下取出的浮点数对象的地址。
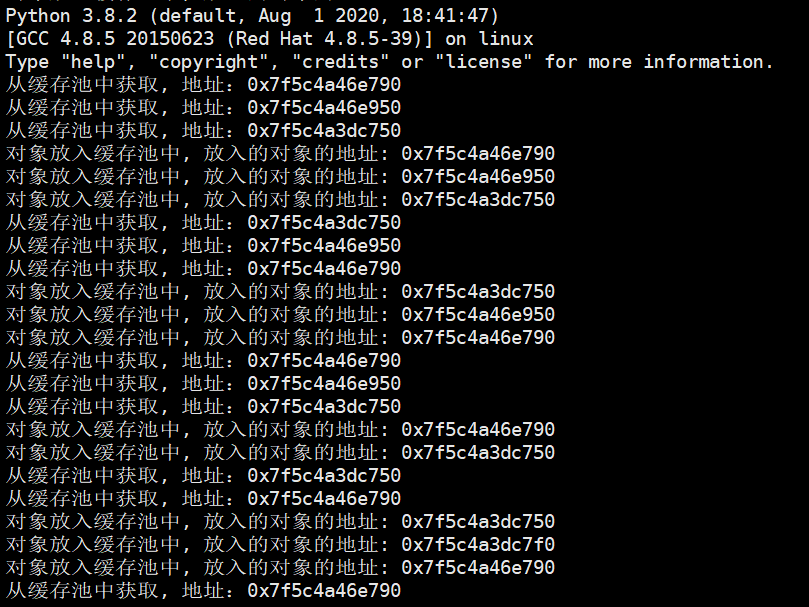
我们看到在解释器刚启动的时候,内部就已经创建出很多对象了,然后我们自己来创建一个对象吧。
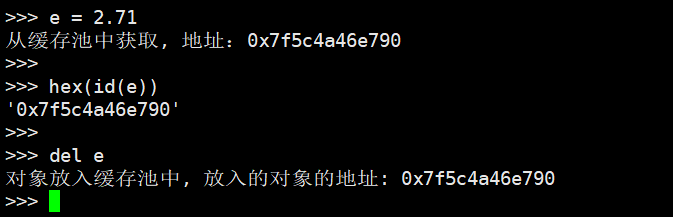
我们第一次创建对象的时候,居然是从缓存池里面获取的,说明在解释器启动的时候那个链表中就已经有空闲对象了。然后我们使用Python获取其id,由于得到的是十进制整型,所以转成16进制,发现地址是一样的。然后放入到缓存池中,放入的对象的地址也是相同的,这和我们得到结论是一致的。
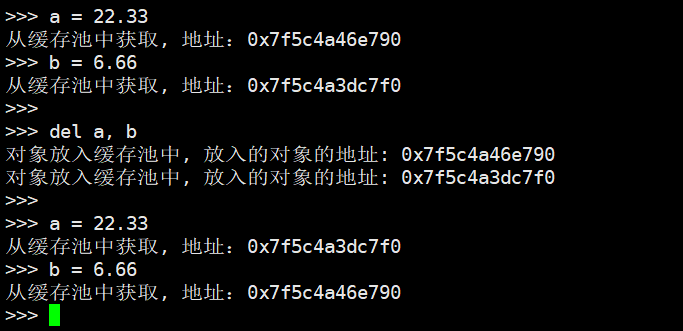
我们再创建新的变量a、b并打印地址,然后删除a、b变量,再重新创建a、b变量、打印地址,结果发现它们存储的对象的地址在删除前后正好是相反的。至于原因,如果思考一下将对象放入缓存池、以及从缓存池获取对象的时候所采取的策略,那么很容易就明白了。
因为del a, b的时候会先删除a,再删除b。删除a的时候,会将a指向的对象作为链表中的第一个元素,然后删除b的时候,会将b指向的对象作为链表中的第一个元素,所以之前a指向的对象就变成了链表中的第二个元素。而获取的时候,也会从链表的头部开始获取,所以当重新创建变量a的时候,其指向的对象实际上使用的是之前变量b指向的对象所占的内存,而一旦获取,那么free_list指针会向后移动;因此创建变量b的时候,其指向的对象显然使用的是之前变量a指向的对象所占的内存。因此前后打印的地址是相反的,所以我们算是通过实践从另一个角度印证了之前分析的结论。
小结
这一篇我们分析了Python中的浮点数在底层的实现方式,之所以选择浮点数是因为浮点数是最简单的了。至于整数,其实并没有那么简单,因为它的值底层是通过数组存储的,而浮点型底层是用一个double存储对应的值,所以更简单一些,我们就先拿浮点数”开刀了”。
然后我们还介绍浮点数的创建和销毁,会调用类型对象内部的tp_dealloc,浮点数的话就是float_dealloc。当然为了保证效率,避免内存的创建和回收,Python底层为浮点数引入了缓存池机制,我们也分析了它的机制。当然浮点数还支持相关的数值型操作,PyFloat_Type中的tp_as_number指向了PyNumberMethods结构体,里面有大量的函数指针,每个指针指向了具体的函数,专门用于浮点数的运算。当然整型也有,只不过指针指向的函数是用于整型运算的。比如相加:对于浮点数来说,PyNumberMethods结构体成员nb_add指向了函数float_add;对于整数来说,nb_add则是指向了long_add。然后我们也以相加为例,看了float_add函数的实现,核心就是将Python中对象的值抽出来,转成C的类型,然后运算,最后再根据运算的结果,创建Python中的对象、返回。当然除了加法,它的减法、乘法、除法都是类似的,有兴趣可以”杀入”floatobject.c中,大肆探索一番。
最后我们修改了PyFloatObject的部分源码,其实就是加上了两个printf语句,对float实例对象的缓存池机制进行了实践,并用之前的结论对结果进行了合理的解释。