不少编程语言中的”字符串”都是使用字符数组(或者称字符序列)来表示,比如C语言和go语言就是这样。
Tags:
via Pocket https://ift.tt/2Zsfwtv original site
February 16, 2021 at 10:08PM
Comments
from: github-actions[bot] on: 3/8/2021
《深度剖析CPython解释器》6. 解密Python中bytes对象的底层实现,以及相关操作 - 古明地盆 - 博客园
《深度剖析CPython解释器》6. 解密Python中bytes对象的底层实现,以及相关操作
楔子
不少编程语言中的”字符串”都是使用**字符数组(或者称字符序列)**来表示,比如C语言和go语言就是这样。
char name[] = "komeiji satori";一个字节最多能表示256个字符,所以对于英文来说足够了,因此一个英文字符占一个字节即可,然而对于那些非英文字符便力不从心了。因此为了表示这些非英文编码,于是多字节编码应运而生—-通过多个字节来表示一个字符。但由于原始字节序列不维护编码信息,因此操作不慎便导致各种乱码现象。
而Python提供的解决方案是使用unicode(在Python3中等价于str)表示字符串,因为unicode可以表示各种字符,不需要关心编码的问题。但在存储或网络通讯时,字符串不可避免地要**序列化成字节序列**。为此,Python除了提供字符串对象之外,还额外提供了字节序列对象—-bytes。

如上图,str对象统一表示一个字符串,不需要关心编码;计算机通过字节序列和存储介质、网络介质打交道,字节序列由bytes对象表示;在存储和传输str对象的时候,需要将其序列化成字节序列,序列化也是编码的过程。
下面我们就来看看bytes对象在底层的数据结构。
PyBytesObject
我们说bytes对象是由若干个字节组成的,显然这是一个变长对象,有多少个字节说明其长度是多少。
//Include/bytesobject.h
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;我们看一下里面的成员对象:
PyObject_VAR_HEAD:变长对象的公共头部ob_shash:保存该字节序列的哈希值,之所以选择保存是因为在很多场景都需要bytes对象的哈希值。而Python在计算字节序列的哈希值的时候,需要遍历每一个字节,因此开销比较大。所以会提前计算一次并保存起来,这样以后就不需要算了,可以直接拿来用,并且bytes对象是不可变的,所以哈希值是不变的。ob_sval:这个和PyLongObject中的ob_digit的声明方式是类似的,虽然声明的时候长度是1, 但具体是多少则取决于bytes对象的字节数量。这是C语言中定义"变长数组"的技巧, 虽然写的长度是1, 但是你可以当成n来用, n可取任意值。显然这个ob_sval存储的是所有的字节,因此Python中的bytes的值,底层是通过字符数组存储的。而且通过注释,我们发现会多申请一个空间,用于存储\0,因为C中是通过\0来表示一个字符数组的结束,但是计算ob_size的时候不包括\0。
我们创建几个不同的bytes对象,然后通过画图感受一下:
val = b””

我们看到一个空的字节序列,底层的ob_savl也是需要一个’\0’的,那么这个结构体实例占多大内存呢?我们说上面ob_sval之外的四个成员,显然每个都是8字节,而ob_savl每个成员都是一个char、也就是占1字节,所以Python中bytes对象占的内存等于32 + ob_sval的长度。而ob_sval里面至少有一个’\0’,因此对于一个空的字节序列,显然占33个字节。注意:ob_size统计的是ob_sval中有效字节的个数,不包括’\0’,但是计算占用内存的时候,显然是需要考虑在内的,因为它确实多占用了一个字节的空间。或者说bytes对象占的内存等于33 + ob_size也是可以的。
>>> val = b""
>>> sys.getsizeof(val)
33
>>>val = b”abc”

>>> val = b"abc"
>>> sys.getsizeof(val)
36 # 32 + 4
>>>bytes对象的行为
介绍bytes对象在底层的数据结构之后,我们要考察bytes对象的行为。我们说实例对象的行为由其类型对象决定,所以bytes对象具有哪些行为,就看bytes类型对象本身定义了哪些操作。bytes类型对象,显然对应PyBytes_Type,根据我们之前介绍的规律,也可以猜出来,它定义在Object/bytesobject.c中。
PyTypeObject PyBytes_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"bytes",
PyBytesObject_SIZE,
sizeof(char),
// ...
&bytes_as_number, /* tp_as_number */
&bytes_as_sequence, /* tp_as_sequence */
&bytes_as_mapping, /* tp_as_mapping */
(hashfunc)bytes_hash, /* tp_hash */
// ...
};到了现在,相信你对类型对象的结构肯定非常熟悉了,因为类型对象都是由PyTypeObject结构体实例化得到的。我们看到tp_as_number,它居然不是0,而是传递了一个指针,说明确实指向了一个PyNumberMethods结构体实例。难道bytes支持数值运算,这显然是不可能的啊,所以我们需要进入bytes_as_number中一探究竟。
static PyNumberMethods bytes_as_number = {
0, /*nb_add*/
0, /*nb_subtract*/
0, /*nb_multiply*/
bytes_mod, /*nb_remainder*/
}
//我们看到它只定义了一个取模操作,也就是%
//看到%估计有人已经明白了,这是格式化
static PyObject *
bytes_mod(PyObject *self, PyObject *arg)
{
if (!PyBytes_Check(self)) {
Py_RETURN_NOTIMPLEMENTED;
}
return _PyBytes_FormatEx(PyBytes_AS_STRING(self), PyBytes_GET_SIZE(self),
arg, 0);
}由此可见,bytes对象只是借用了%运算实现了格式化,谈不上数值运算,虚惊一场。不过由此也看到了Python的动态特性,即使是相同的操作,但如果是不同类型的对象执行的话,也会有不同的表现。
>>> info = b"name: %s, age: %d"
>>> info % (b"satori", 16)
b'name: satori, age: 16'
>>>除了tp_as_number,PyBytes_Type还给tp_as_sequence成员传递了bytes_as_sequence指针,说明bytes对象支持序列操作。显然这是肯定的,而且bytes对象显然是序列型对象,所以序列型操作才是我们的研究的重点,下面看看bytes_as_sequence的定义。
static PySequenceMethods bytes_as_sequence = {
(lenfunc)bytes_length, /*sq_length*/
(binaryfunc)bytes_concat, /*sq_concat*/
(ssizeargfunc)bytes_repeat, /*sq_repeat*/
(ssizeargfunc)bytes_item, /*sq_item*/
0, /*sq_slice*/
0, /*sq_ass_item*/
0, /*sq_ass_slice*/
(objobjproc)bytes_contains /*sq_contains*/
};根据定义我们看到,bytes对象支持的序列型操作一共有5个:
sq_length:查看序列的长度sq_concat:将两个序列合并为一个sq_repeat:将序列重复多次sq_item:根据索引获取指定的下表, 得到一个整型;如果是切片,那么还会得到一个bytes对象sq_contains:判断某个序列是不是在该序列中,显然它等价于Python中的in操作
查看序列长度:
显然这是最简单的,直接获取ob_size即可,比如:val = b”abcde”,那么长度就是5。
static Py_ssize_t
bytes_length(PyBytesObject *a)
{
return Py_SIZE(a);
}将两个序列合并为一个:
>>> a = b"abc"
>>> b = b"def"
>>> a + b
b'abcdef'
>>>而且我们看到这里相当于是加法运算,我们很容易想到会是PyNumberMethods中的nb_add,比如:PyLongObject对应的long_add、PyFloatObject对应的float_add,但对于bytes对象而言,加法操作对应PySequenceMethods的sq_concat。所以我们看到Python中的同一个操作符,在底层会对应不同的函数,比如:long_add和float_add、以及这里的bytes_concat,在Python的层面都是+这个操作符。然后我们看看底层是怎么对两个字节序列进行相加的。
static PyObject *
bytes_concat(PyObject *a, PyObject *b)
{
//两个局部变量,用于维护缓冲区
Py_buffer va, vb;
//result用于保存结果
PyObject *result = NULL;
//将缓冲区的长度设置为-1, 可以认为此时缓冲区啥也没有
va.len = -1;
vb.len = -1;
//将a、b中ob_sval拷贝到缓冲区中,拷贝成功返回0,拷贝失败返回非0
//如果下面的条件不成功, 就意味着拷贝失败了, 说明至少有一个老铁不是bytes类型
if (PyObject_GetBuffer(a, &va, PyBUF_SIMPLE) != 0 ||
PyObject_GetBuffer(b, &vb, PyBUF_SIMPLE) != 0) {
//然后设置异常,PyExc_TypeError表示TypeError(类型错误),专门用来指对一个对象执行了它所不支持的操作
PyErr_Format(PyExc_TypeError, "can't concat %.100s to %.100s",
Py_TYPE(b)->tp_name, Py_TYPE(a)->tp_name);
//比如:"123" + 123, 会得到: TypeError: can't concat int to bytes, 和这里设置的异常信息是一样的
//这里直接跳转到done
goto done;
}
//这里是判断是否有一方长度为0, 如果a长度为0,那么相加之后结果就是b
if (va.len == 0 && PyBytes_CheckExact(b)) {
//将b拷贝给result
result = b;
//增加result的引用计数
Py_INCREF(result);
//跳转
goto done;
}
//和上面同理,如果b长度为0,那么相加之后的结果就是a
if (vb.len == 0 && PyBytes_CheckExact(a)) {
//将a拷贝给result
result = a;
//增加引用计数
Py_INCREF(result);
//跳转
goto done;
}
//这里是判断两个字节序列合并之后,长度是否超过限制,因为不允许超过PY_SSIZE_T_MAX
//所以更直观的写法应该是 if (va.len + vb.len > PY_SSIZE_T_MAX), 但是这个条件基本不可能满足,除非你写恶意代码
if (va.len > PY_SSIZE_T_MAX - vb.len) {
PyErr_NoMemory();
goto done;
}
//否则话,声明指定容量PyBytesObject
result = PyBytes_FromStringAndSize(NULL, va.len + vb.len);
if (result != NULL) {
//将缓冲区va里面内容拷贝到result的ob_sval中,拷贝的长度为va.len
//PyBytes_AS_STRING是一个宏,用于获取PyBytesObject中的ob_sval
memcpy(PyBytes_AS_STRING(result), va.buf, va.len);
//然后将缓冲区vb里面的内容拷贝到result的ob_sval中,拷贝的长度为vb.len,但是从va.len的位置开始拷贝, 不然会把内容覆盖掉
memcpy(PyBytes_AS_STRING(result) + va.len, vb.buf, vb.len);
}
done:
//如果长度不会-1,那么要将缓冲区里面的内容释放掉,否则可能导致内存泄漏
if (va.len != -1)
PyBuffer_Release(&va);
if (vb.len != -1)
PyBuffer_Release(&vb);
//返回result
return result;
}虽然代码很长,但是不难理解。不过可能有人认为为什么非要先将a、b的内容拷贝到Py_buffer里面,再通过Py_buffer拷贝到result里面去呢?直接拷贝不可以吗?答案是Py_buffer提供了一套操作对象缓冲区的统一接口,屏蔽不同类型对象的内部差异。
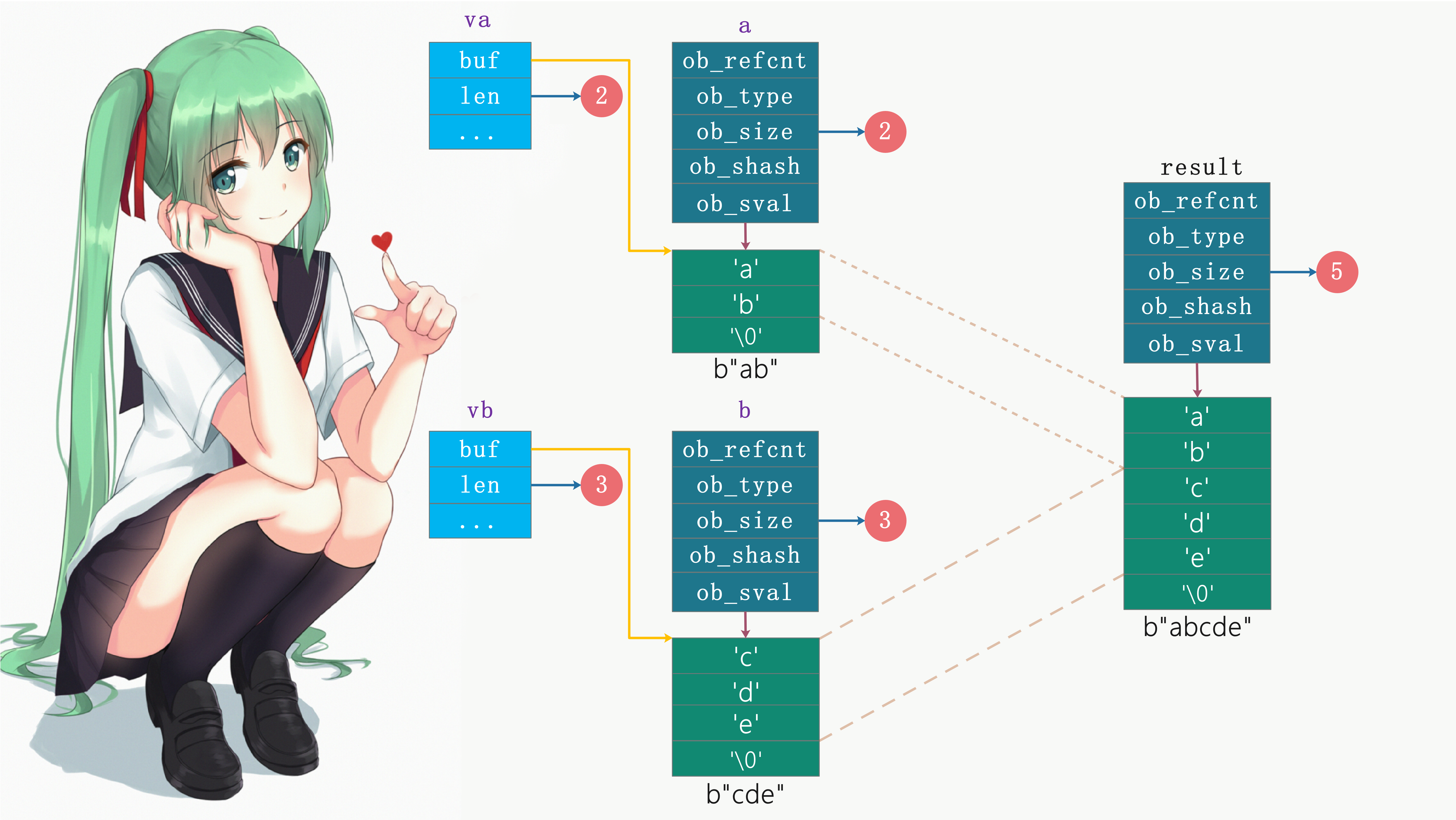
将序列重复多次:
>>> a = b"abc"
>>> a * 3
b'abcabcabc'
>>> a * -1
b'' # 如果乘上一个负数,等于乘上0,那么会得到一个空的字节序列
>>>然后我们看看底层的实现:
static PyObject *
bytes_repeat(PyBytesObject *a, Py_ssize_t n)
{
Py_ssize_t i;
Py_ssize_t j;
Py_ssize_t size;
PyBytesObject *op;
size_t nbytes;
//如果n小于0, 那么等于0
if (n < 0)
n = 0;
//这里条件写成Py_SIZE(a) * n > PY_SSIZE_T_MAX更容易理解
if (n > 0 && Py_SIZE(a) > PY_SSIZE_T_MAX / n) {
//先计算相乘之后字节序列的长度是否超过最大限制,如果超过了,直接报错
PyErr_SetString(PyExc_OverflowError,
"repeated bytes are too long");
return NULL;
}
//计算Py_SIZE(a) * n得到size
size = Py_SIZE(a) * n;
if (size == Py_SIZE(a) && PyBytes_CheckExact(a)) {
//如果两者相等,那么证明n = 1,直接增加引用计数,然后返回a即可
Py_INCREF(a);
return (PyObject *)a;
}
//类型转化,此时是size_t类型,相当于无符号64位整型
nbytes = (size_t)size;
//PyBytesObject_SIZE是一个宏,表示PyBytesObject的基本大小
//它是一个宏,等价于(offsetof(PyBytesObject, ob_sval) + 1), 显然是33
//所以nbytes + PyBytesObject_SIZE就是bytes对象所需要的空间
//如果nbytes + PyBytesObject_SIZE还小于等于nbytes, 所以相加之后size_t类型存不下了
//说明超过所占内存的极限了
if (nbytes + PyBytesObject_SIZE <= nbytes) {
PyErr_SetString(PyExc_OverflowError,
"repeated bytes are too long");
return NULL;
}
//申请空间,大小为PyBytesObject_SIZE + nbytes
op = (PyBytesObject *)PyObject_MALLOC(PyBytesObject_SIZE + nbytes);
if (op == NULL)
//返回NULL,表示申请失败
return PyErr_NoMemory();
//PyObject_INIT_VAR是一个宏,设置ob_type和ob_size
(void)PyObject_INIT_VAR(op, &PyBytes_Type, size);
//设置ob_shash为-1
op->ob_shash = -1;
//将ob_sval最后一位设置为'\0'
op->ob_sval[size] = '\0';
if (Py_SIZE(a) == 1 && n > 0) {
//显然这里是在a对应的bytes对象长度为1时,所走的逻辑
//直接将op->ob_sval里面元素设置a->ob_sval[0], 设置n个
memset(op->ob_sval, a->ob_sval[0] , n);
return (PyObject *) op;
}
i = 0;
//否则将a -> ob_sval拷贝到op -> ob_sval中, 拷贝n次, 因为size = Py_SIZE(a) * n;
//这里是先拷贝了一次
if (i < size) {
memcpy(op->ob_sval, a->ob_sval, Py_SIZE(a));
i = Py_SIZE(a);
}
//然后拷贝n - 1次
while (i < size) {
j = (i <= size-i) ? i : size-i;
memcpy(op->ob_sval+i, op->ob_sval, j);
i += j;
}
return (PyObject *) op;
}根据索引获取指定元素:
>>> val = b"abcdef"
>>> val[1], type(val[1])
(98, <class 'int'>)
>>>
>>> val[1: 4], type(val[1:4])
(b'bcd', <class 'bytes'>)
>>>然后我们看看底层的实现:
static PyObject *
bytes_item(PyBytesObject *a, Py_ssize_t i)
{
//如果i < 0或者 i >= a的ob_size,那么会报错:索引越界
//但是我们记得Python支持负数索引的啊,是的,只不过会手动帮你变成正的
//因为C是不支持负数索引的,所以通过C的索引获取,那么索引一定是正的
//因此我们填上的负数,Python会帮你加上长度。比如:长度为5,但是我们写的索引为-1, 那么Python会帮你变成4之后再获取
if (i < 0 || i >= Py_SIZE(a)) {
PyErr_SetString(PyExc_IndexError, "index out of range");
return NULL;
}
//我们看到获取第i个元素之后直接转成了PyLongObject,然后返回指针
return PyLong_FromLong((unsigned char)a->ob_sval[i]);
}那切片呢?切片的话对应bytes_subscript,但它不是在PySequenceMethods tp_as_sequence里面,而是在PyMappingMethods bytes_as_mapping里面,它是一个映射操作。
static PySequenceMethods bytes_as_sequence = {
(lenfunc)bytes_length, /*sq_length*/
(binaryfunc)bytes_concat, /*sq_concat*/
(ssizeargfunc)bytes_repeat, /*sq_repeat*/
(ssizeargfunc)bytes_item, /*sq_item*/
0, /*sq_slice*/
0, /*sq_ass_item*/
0, /*sq_ass_slice*/
(objobjproc)bytes_contains /*sq_contains*/
};
//我们看到映射操作,bytes对象中只有两个,一个bytes_length获取长度,这个在bytes_as_sequence中已经实现了,还有一个就是bytes_subscript进行切片操作
static PyMappingMethods bytes_as_mapping = {
(lenfunc)bytes_length,
(binaryfunc)bytes_subscript,
0,
};因为映射操作只有两个,一个是重复的,还有一个是必须要在这里说的,所以映射操作我们就放在这里介绍了。
static PyObject*
bytes_subscript(PyBytesObject* self, PyObject* item)
{
//参数是self和item,那么在Python的层面上就类似于self[item]
//检测item,看它是不是一个整型
if (PyIndex_Check(item)) {
//如果是转成Ssize_t
Py_ssize_t i = PyNumber_AsSsize_t(item, PyExc_IndexError);
if (i == -1 && PyErr_Occurred())
return NULL;
//如果i小于0,那么将i加上序列的长度,得到正数索引
if (i < 0)
i += PyBytes_GET_SIZE(self);
if (i < 0 || i >= PyBytes_GET_SIZE(self)) {
PyErr_SetString(PyExc_IndexError,
"index out of range");
return NULL;
}
//得到整型
return PyLong_FromLong((unsigned char)self->ob_sval[i]);
}
//检测是否是一个切片
else if (PySlice_Check(item)) {
//起始、终止、步长、拷贝的字节个数、循环变量
Py_ssize_t start, stop, step, slicelength, i;
size_t cur; //拷贝的字节所在的位置
//两个缓存
char* source_buf;
char* result_buf;
//返回的结果
PyObject* result;
//这里是会将item解包
if (PySlice_Unpack(item, &start, &stop, &step) < 0) {
return NULL;
}
//得到拷贝的字节个数比如:ob_sval长度为9, 但是未必拷贝9个,所以这个slicelength是计算的拷贝的字节个数
slicelength = PySlice_AdjustIndices(PyBytes_GET_SIZE(self), &start,
&stop, step);
//slicelength小于等于0的话,直接返回空的字节序列,比如val[3: 2],显然此时是不循环的,因为start对应的位置在end之后,而且步长为正
if (slicelength <= 0) {
return PyBytes_FromStringAndSize("", 0);
}
//如果起始位置为0,步长为1,且拷贝的字节个数等于字节序列的长度
else if (start == 0 && step == 1 &&
slicelength == PyBytes_GET_SIZE(self) &&
PyBytes_CheckExact(self)) {
//那么增加引用计数,直接返回
Py_INCREF(self);
return (PyObject *)self;
}
else if (step == 1) {
//如果步长是1,那么从start开始拷贝,拷贝slicelength个字字节
return PyBytes_FromStringAndSize(
PyBytes_AS_STRING(self) + start,
slicelength);
}
else {
//走到这里,说明步长不是1,只能一个一个拷贝了
source_buf = PyBytes_AS_STRING(self);
//创建PyBytesObject对象,空间为slicelength
result = PyBytes_FromStringAndSize(NULL, slicelength);
if (result == NULL)
return NULL;
//拿到内部的ob_sval
result_buf = PyBytes_AS_STRING(result);
//从start开始然后一个字节一个字节的拷贝过去
//start开始拷贝,依旧循环slicelength,通过cur记录拷贝的位置,然后每次循环都加上步长step
for (cur = start, i = 0; i < slicelength;
cur += step, i++) {
result_buf[i] = source_buf[cur];
}
//返回
return result;
}
}
//item要么是整数、要么是切片,走到这里说明不满足条件
else {
//比如:item我们传递了一个字符串,显然此时在通过这种方式获取的话,这属于字典的操作
//所以抛出TypeError异常
PyErr_Format(PyExc_TypeError,
"byte indices must be integers or slices, not %.200s",
Py_TYPE(item)->tp_name);
//返回空
return NULL;
}
}所以从底层我们可以看到,Python为我们做的事情是真的不少,我们通过一个简单的切片,在底层要这么多行代码。不过在我们分析完逻辑之后,会发现其实也不过如此,毕竟逻辑很好理解。
但是在Python中,索引操作和切片操作,我们都可以通过__getitem__实现。
class A:
def __getitem__(self, item):
return item
a = A()
print(a[123]) # 123
print(a["name"]) # name
print(a[1: 5]) # slice(1, 5, None)
print(a[1: 5: 2]) # slice(1, 5, 2)
print(a["yo": "ha": "哼哼"]) # slice('yo', 'ha', '哼哼')
# 通过__getitem__,我们可以同时实现切片、索引获取,但是当item为字符串时,我们还可以实现字典操作
# 当然这部分内容,我们会在后面系列中分析类的时候介绍。判断一个序列是否在指定的序列中:
>>> val = b"abcdef"
>>> b"abc" in val
True
>>> b"cbd" in val
False
>>>如果让你来实现的话,显然是两层for循环,那么Python是怎么做的呢?
static int
bytes_contains(PyObject *self, PyObject *arg)
{
//比如: b"abc" in b"abcde"会调用这里的bytes_contains
//self就是b"abcde"对应的PyBytesObject的指针,arg是b"abc"对应的PyBytesObject的指针
//显然这里调用了_Py_bytes_contains, 传入了self -> ob_sval, self -> ob_size, arg
return _Py_bytes_contains(PyBytes_AS_STRING(self), PyBytes_GET_SIZE(self), arg);
}
//上面的源码没有说明,显然是在bytesobject.c中
//但是_Py_bytes_contains位于bytes_methods.c中
_Py_bytes_contains(const char *str, Py_ssize_t len, PyObject *arg)
{
//将arg转成整型, 但是显然只有当arg -> ob_savl的有效字节为1时才可以这么做
Py_ssize_t ival = PyNumber_AsSsize_t(arg, NULL);
if (ival == -1 && PyErr_Occurred()) {
//所以如果ival == -1 && PyErr_Occurred(),说明arg -> ob_sval的有效字节数大于1
Py_buffer varg;//缓冲区
Py_ssize_t pos;//遍历位置
PyErr_Clear();//这里将异常清空
//将arg -> ob_sval设置到缓存区中
if (PyObject_GetBuffer(arg, &varg, PyBUF_SIMPLE) != 0)
return -1;
//调用stringlib_find找到其位置,里面也是使用了循环
pos = stringlib_find(str, len,
varg.buf, varg.len, 0);
PyBuffer_Release(&varg); //释放缓冲区
//如果pos大于0确实找到了,否则返回-1
return pos >= 0;
}
//否则说明字节不合法
if (ival < 0 || ival >= 256) {
PyErr_SetString(PyExc_ValueError, "byte must be in range(0, 256)");
return -1;
}
//走到这里说明是单个字节,直接调用C中memchr去寻找即可
return memchr(str, (int) ival, len) != NULL;
}效率问题
我们知道Python中对于不可变对象运算的处理方式就是,再创建一个新的。所以三个bytes对象a、b、c相加时,那么会先根据a + b创建新的临时对象,然后再根据”临时对象+c”创建新的对象,返回指针。所以:
result = b""
for _ in bytes_list:
result += _这是一种效率非常低下的做法,因为涉及大量临时对象的创建和销毁,不仅是这里bytes,后面即将分析的字符串也是同样的道理。官方推荐的做法是,使用join,字符串和字节序列都可以对一个列表进行join,将列表里面的多个字符串或者字节序列join在一起。
举个Python中的例子,我们以字符串为例,字节序列同样如此:
def bad():
s = ""
for _ in range(1, 10):
s += str(_)
return s
def good():
l = []
for _ in range(1, 10):
l.append(str(_))
return "".join(l)
def better():
return "".join(str(_) for _ in range(1, 10))
def best():
return "".join(map(str, range(1, 10)))字节序列缓冲池
为了优化单字节bytes对象的创建效率,Python底层内部维护了一个缓冲池。
static PyBytesObject *characters[UCHAR_MAX + 1];Python内部创建单字节bytes对象时,先检查目标对象是否已在缓冲池中。PyBytes_FromStringAndSize函数是负责创建bytes对象的通用接口,同样位于 Objects/bytesobject.c 中:
PyObject *
PyBytes_FromStringAndSize(const char *str, Py_ssize_t size)
{
//PyBytesObject对象的指针
PyBytesObject *op;
if (size < 0) {
//显然size不可以小于0
PyErr_SetString(PyExc_SystemError,
"Negative size passed to PyBytes_FromStringAndSize");
return NULL;
}
//如果size为1表名创建的是单字节对象,当然str不可以为NULL, 而且获取到的字节必须要在characters里面
if (size == 1 && str != NULL &&
(op = characters[*str & UCHAR_MAX]) != NULL)
{
#ifdef COUNT_ALLOCS
_Py_one_strings++;
#endif
//增加引用计数,返回指针
Py_INCREF(op);
return (PyObject *)op;
}
//否则话创建新的PyBytesObject,此时是个空
op = (PyBytesObject *)_PyBytes_FromSize(size, 0);
if (op == NULL)
return NULL;
if (str == NULL)
return (PyObject *) op;
//不管size是对少,都直接拷贝即可
memcpy(op->ob_sval, str, size);
//但是size是1的话,除了拷贝还会放到缓存池characters中
if (size == 1) {
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
//返回其指针
return (PyObject *) op;
}由此可见,当 Python 程序开始运行时,字符缓冲池是空的。随着单字节 bytes*对象的创建,缓冲池中的对象慢慢多了起来。
这样一来,字符对象首次创建后便在缓冲池中缓存起来;后续再次使用时, Python 直接从缓冲池中取,避免重复创建和销毁。与前面章节介绍的小整数对象池一样,字符对象只有为数不多的 256 个,但使用频率非常高。缓冲池技术作为一种以时间换空间的优化手段,只需较小的内存为代价,便可明显提升执行效率。
>>> a1 = b"a"
>>> a2 = b"a"
>>> a1 is a2
True
>>>
>>> a1 = b"ab"
>>> a2 = b"ab"
>>> a1 is a2
False
>>>显然此时不需要我解释了,单字节bytes对象会缓存起来,不是单字节则不会缓存。
bytearray对象
除了bytes对象之外,Python中还有一个bytearray对象,它和bytes对象类似,只不过bytes对象是不可变的,而bytearray对象是可变的。所以就不单独分析了,这里简单提一嘴。
# 传入一个整型组成的列表创建bytearray对象
s = bytearray([99, 100, 101])
print(s) # bytearray(b'cde')
# 传入一个bytes对象创建bytearray对象
s = bytearray(b"abc")
print(s)
# 传入一个字符串,同时指定encoding编码创建bytearray对象
s = bytearray("古明地觉", encoding="utf-8")
print(s) # bytearray(b'\xe5\x8f\xa4\xe6\x98\x8e\xe5\x9c\xb0\xe8\xa7\x89')
# 我们对s进行decode会直接得到字符串
print(s.decode("utf-8")) # 古明地觉
# 注意:bytearray对象是可以变的
# 如果是中文,为了防止出现乱码,所以一次要改变3个字节
s[-3:] = "恋".encode("utf-8")
print(s) # bytearray(b'\xe5\x8f\xa4\xe6\x98\x8e\xe5\x9c\xb0\xe6\x81\x8b')
print(s.decode("utf-8")) # 古明地恋
# 我们同样可以根据索引、切片获取
s = bytearray(b"abc")
# 获取单个元素也会得到整型,这一点和bytes对象是一样的
print(s[0], s[1], s[2]) # 97 98 99
# 通过切片得到bytearray
print(s[:2]) # bytearray(b'ab')
# 对多个bytearray对象进行join, 会得到一个bytes对象
print(b"--".join([bytearray(b"abc"), bytearray(b"def")])) # b'abc--def'因此把bytearray对象想象成可变的bytes对象即可,它的使用和bytes对象非常类似,一些操作的行为也是一样的,所以就不单独分析了,下一篇将会分析Python中的字符串。
小结
这次我们分析了bytes对象的底层实现,我们说:
bytes对象是一个变长、不可变对象,内部的值是通过一个C的字符数组来维护的;bytes也是序列型操作,它支持的操作在bytes_as_sequence中;Python内部维护字符缓冲池来优化单字节bytes对象的创建和销毁操作;缓冲池是一种常用的以空间换时间的优化技术;