这次我们来看一下Python中类的继承与属性查找机制,我们说Python是支持类的多继承的,在查找属性的时候会沿着继承链不断找下去。那么下面我们就来深入地考察一下类的继承与属性查找在底层是如何实现的。
Tags:
via Pocket https://ift.tt/2ZnX4SQ original site
February 16, 2021 at 10:14PM
Comments
from: github-actions[bot] on: 3/8/2021
《深度剖析CPython解释器》18. Python类机制的深度解析(第二部分): 类的多继承与属性查找 - 古明地盆 - 博客园
《深度剖析CPython解释器》18. Python类机制的深度解析(第二部分): 类的多继承与属性查找
楔子
这次我们来看一下Python中类的继承与属性查找机制,我们说Python是支持类的多继承的,在查找属性的时候会沿着继承链不断找下去。那么下面我们就来深入地考察一下类的继承与属性查找在底层是如何实现的。
深入class
我们知道Python里面有很多以双下划线开头、双下划线结尾的方法,我们称之为魔法方法。Python中的每一个操作符,都被抽象成了一个魔法方法。比如整数3,整数可以相减,这就代表int这个类里面肯定定义了__sub__函数。字符串不能相减,代表str这个类里面没有__sub__函数;而整数和字符串都可以执行加法操作,显然int、str内部都定义了__add__函数。
class MyInt(int):
def __sub__(self, other):
return int.__sub__(self, other) * 3
a = MyInt(4)
b = MyInt(1)
print(a - b) # 9我们自己实现了一个类,继承自int。当我执行a - b的时候,肯定执行对应的__sub__方法,然后调用int的__sub__方法,得到结果之后再乘上3,逻辑上没有问题。但是问题来了,首先调用int.__sub__的时候,我们知道Python肯定是调用long_as_number中的long_sub指向的函数,这些在之前已经说过了,但我想问的是int.__sub__(self, other)里面的参数类型显然都应该是int,但是我们传递的是MyInt,那么Python虚拟机是怎么做的呢?
目前带着这些疑问,先来看一张草图,我们后面会一点一点揭开:
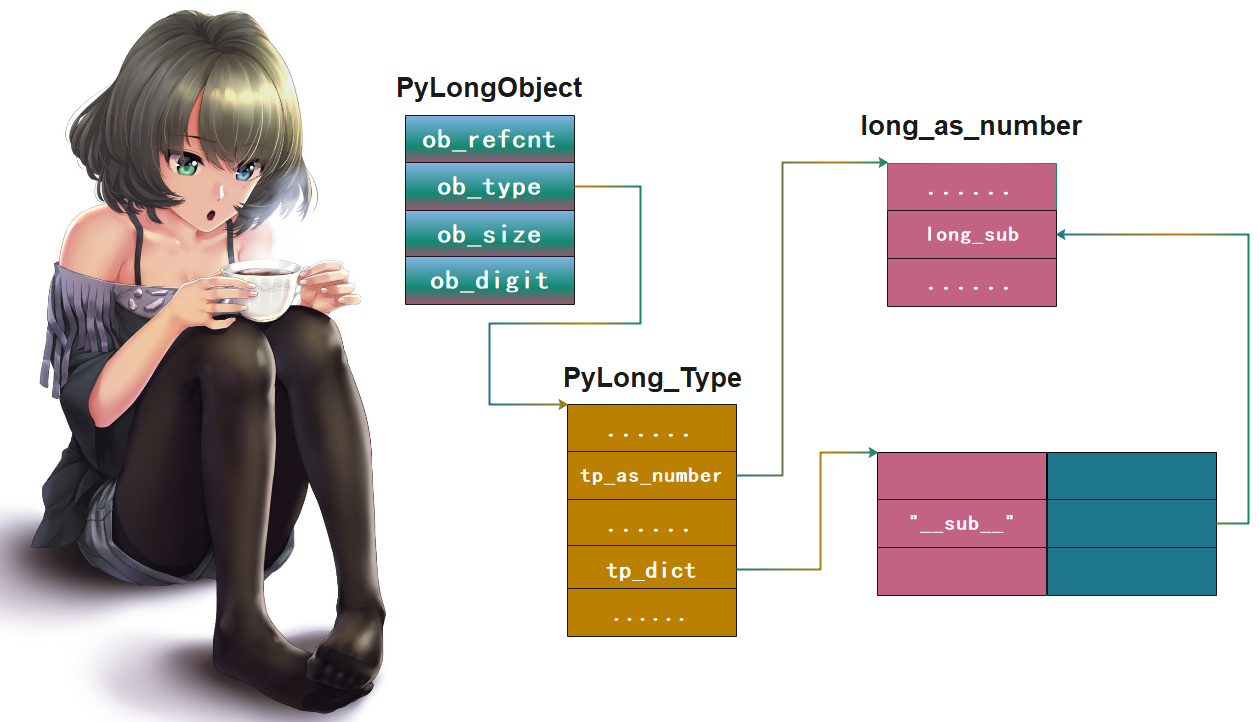
图中的”__sub__“对应的value并不是一个直接指向long_sub函数的指针,而是一个别的什么东西,对其进行调用,调用的结果指向long_sub函数。至于这个东西是什么,以及具体细节,我们后面会详细说。
另外我们知道,一个对象能否被调用,取决于它的类型对象中是否定义了__call__函数。因此:所谓调用,就是执行类型对象中的tp_call指向的函数。
class A:
def __call__(self, *args, **kwargs):
return "我是CALL,我被尻了"
a = A()
print(a()) # 我是CALL,我被尻了在Python底层,实际上是通过一个PyObject_Call函数对实例对象a进行操作。
a = 1
a()
# TypeError: 'int' object is not callable我们看到一个整数对象是不可调用的,这显然意味着int这个类里面没有__call__函数,换言之PyLongObject结构体对应的ob_type域里面的tp_call为NULL。
# 但是我们通过反射打印的时候,发现int是有__call__函数的啊
print(hasattr(int, "__call__")) # True
# 但其实这个__call__不是int里面的,而是type的
print("__call__" in dir(int)) # False
print("__call__" in dir(type)) # True
print(int.__call__) # <method-wrapper '__call__' of type object at 0x00007FFAE22C0D10>
# hasattr和类的属性查找一样,如果找不到会自动到对应的类型对象里面去找
# int的类型是type, 而type里面有__call__, 因此即便int里面没有, hasattr(int, "__call__")依旧是True
a1 = int("123")
a2 = int.__call__("123")
a3 = type.__call__(int, "123")
# 以上三者的本质是一样的
print(a1, a2, a3) # 123 123 123
# 之前说过, 当一个对象加上括号的时候, 本质上调用其类型对象里面的__call__函数
# a = 3
# 那么a()就相当于调用int里面的__call__函数,但是int里面没有,就直接报错了
# 可能这里就有人问了, 难道不会到type里面找吗?答案是不会的,因为type是元类, 是用来生成类的
# 如果还能到type里面找, 那么调用type的__call__生成的结果到底算什么呢?是类对象?可它又明明是实例对象加上括号调用的。显然这样就乱套了
# 因此实例对象找不到, 会到类对象里面找, 如果类对象再找不到, 就不会再去元类里面找了, 而是会去父类里面找
class A:
def __call__(self, *args, **kwargs):
print(self)
return "我被尻了"
class B(A):
pass
class C(B):
pass
c = C()
print(c())
"""
<__main__.C object at 0x000002282F3D9B80>
我被尻了
"""
# 此时我们看到, 给C的实例对象加括号的时候, C里面没有__call__函数, 这个时候是不会到元类里面找的
# 还是之前的结论,实例对象找不到属性,会去类对象里面找,然而即便此时类对象里面也没有,也不会到元类type里面找,这时候就看父类了
# 我们看对于我们上面的例子,给C的实例对象加括号的时候,会执行C这个类里面的__call__
# 但是它没有,所以找不到。然而它继承的父类里面有__call__
# 因此会执行继承的父类的__call__方法, 并且里面的self还是C的实例对象因此一个对象的属性查找,我们可以得到如下规律:首先从对象本身进行查找,没有的话会从该对象的类型对象中进行查找,还没有的话就从类型对象所继承的父类中进行查找。
class A:
def __call__(self, *args, **kwargs):
print(self)
return "我被尻了"
class B(A):
pass
class C(B):
pass
c = C()
print(c())还是以这段代码为例:当调用类型对象C的时候,本质上是执行类型对象C的类型对象(type)里面的__call__函数。当调用实例对象c的时候,本质上是执行类型对象C里面的__call__函数,但是C里面没有,这个时候怎么做?显然是沿着继承链进行属性查找,去找C继承的类里面的__call__函数。

可能有人好奇,为什么没有object?答案是object内部没有__call__函数,所以object.__call__实际上就是type.__call__。
print(object.__call__) # <method-wrapper '__call__' of type object at 0x00007FFD0A896B50>因为object的类型是type,所以调用object的时候,实际上执行的是type.__call__(object)。
所以所有的类对象都是可以调用的,因为type是它们的类型对象,而type内部是有__call__函数的。但是默认情况下实例对象是不可调用的,如果实例对象的类型对象、以及该类型对象所继承的类中没有定义__call__函数的话,因为沿着继承链查找的时候,会挨个进行搜索,当搜索到object时发现还没有__call__函数的话,那么就报错了。
所以一个整数对象是不可调用的,但是我们发现这并不是在编译的时候就能够检测出来的错误,而是在运行时才能检测出来、会在运行时通过函数 PyObject_CallFunctionObjArgs 确定。所以a = 1;a()明明会报错,但Python还是成功编译了。
为什么会是这样呢?我们知道一个对象对应的类型对象都会有tp_dict这个域,这个域指向一个PyDictObject,表示这个对象支持哪些操作,而这个PyDictObject对象必须要在运行时动态构建。所以都说Python效率慢,一个原因是所有对象都分配在堆上,还有一个原因就是一个对象很多属性或者操作、甚至是该对象是什么类型都需要在运行时动态构建,从而也就造成了Python运行时效率不高。
而且我们发现,像int、str、dict等内建对象可以直接使用。这是因为Python解释器在启动时,会对这些内建对象进行初始化的动作。这个初始化的动作会动态地在这些内建对象对应的PyTypeObject中填充一些重要的东西,其中当然也包括填充tp_dict,从而让这些内建对象具备生成实例对象的能力。这个对内建对象进行初始化的动作就从函数 PyType_Ready 拉开序幕。
Python底层通过调用函数 PyType_Ready 对内建对象进行初始化,实际上, PyType_Ready 不仅仅是处理内建对象,还会处理class对象,并且 PyType_Ready 对于内建对象和class对象的作用还不同。比如PyList_Type,它在底层是已经被定义好了的,所以在解释器启动的时候就直接创建,并且是全局对象。只不过我们说它还是不够完善,还需要再打磨一下,而这一步就交给了 PyType_Ready 。
但是对于我们自定义的类就不同了,我们说内建的类在底层都是定义好了的,随着解释器启动的时候就已经创建了,已经具备了绝大部分功能,然后再交给 PyType_Ready 完善一下,内建的类就形成了;但是对于我们自定义的类来说, PyType_Ready 做的工作只是很小的一部分,因为我们使用class定义的类、假设是class A,Python一开始是并不知道的。Python解释器在启动的时候,不可能直接就创建一个PyA_Type出来,因此对于我们自定义的类来说,需要在解释执行的时候进行申请内存、创建、初始化整个动作序列等等一系列步骤。
下面我们就以Python中的type类型对象入手,因为它比较特殊。Python中的type在底层对应PyType_Type,我们说Python中type是int、str、dict、object、type等内建对象的元类。但是在底层,这些所有的内建类型都是一个PyTypeObject对象。
int: PyLong_Typestr: PyUnicode_Typetuple: PyTuple_Typedict: PyDict_Typetype: PyType_Type
从名字也能看出来规律,这些内建对象在Python底层中,都是一个PyTypeObject对象、或者说一个PyTypeObject结构体实例。尽管在Python中说type是所有类对象(所有内建对象+class对象)的元类,但是在Python底层它们都是同一个类型、也就是同一个结构体的不同实例。
处理基类和type信息
我们来看一下 PyType_Ready ,它位于 Objects / typeobject.c 中。
int
PyType_Ready(PyTypeObject *type)
{
//这里的参数显然是类型对象, 以<class 'type'>为例
//__dict__和__bases__, 因为可以继承多个类, 所以是bases, 当然不用想这些基类也都是PyTypeObject对象
PyObject *dict, *bases;
//还是继承的基类,显然这个是object,对应PyBaseObject_Type,因为py3中,所有的类都是默认继承的
PyTypeObject *base;
Py_ssize_t i, n;
//......
//......
//获取类型对象中tp_base域指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
//如果基类为空、并且该类本身不是object, 那么将该类的基类设置为object、即PyBaseObject_Type
//所以我们之前看一些类型对象的底层定义的时候, 发现源码中tp_base域对应的是0, 因为tp_base是在这里进行设置的
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
//如果基类不是NULL, 但是基类的属性字典是NULL
if (base != NULL && base->tp_dict == NULL) {
//那么对基类进行初始化, 所以这里是一个是一个递归调用
if (PyType_Ready(base) < 0)
goto error;
}
//如果该类型对象的ob_type为空NULL但是基类不为NULL, 那么将该类型对象的ob_type设置为基类的ob_type
//为什么要做这一步, 我们后面会详细说
//但其实base != NULL是没必要的, 因为只有当类型为PyBaseObject_type时, base才为NULL
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);
//这里是设置__bases__, 后面说
bases = type->tp_bases;
if (bases == NULL) {
if (base == NULL)
bases = PyTuple_New(0);
else
bases = PyTuple_Pack(1, base);
if (bases == NULL)
goto error;
type->tp_bases = bases;
}
//构造属性字典, 后面说
dict = type->tp_dict;
if (dict == NULL) {
dict = PyDict_New();
if (dict == NULL)
goto error;
type->tp_dict = dict;
}
//......
}对于指定了tb_base的类对象,当然就使用指定的基类,而对于没有指定tp_base的类对象,Python将为其指定一个默认的基类: PyBaseObject_Type ,当然这个东西就是Python中的object。现在我们看到PyType_Type的tp_base指向了PyBaseObject_Type,这在Python中体现的就是type继承自object、或者说object是type的父类。但是所有的类底层对应的结构体的ob_type域又都指向了PyType_Type,包括object,因此我们又说type是包括object在内的所有类的类(元类)。
在获得了基类之后,就会判断基类是否被初始化,如果没有,则需要先对基类进行初始化。可以看到, 判断初始化是否完成的条件是base->tp_dict是否为NULL,这符合之前的描述。对于内建对象的初始化来说,在Python解释器启动的时候,就已经作为全局对象存在了,剩下的就是小小的完善一下,比如对tp_dict进行填充。
然后设置ob_type信息,实际上这个ob_type就是__class__返回的信息。首先 PyType_Ready 函数里面接收的是一个PyTypeObject对象,我们知道这个在Python中就是类对象。因此这里是设置这些类对象的ob_type,那么对应的ob_type显然就是元类metaclass,我们自然会想象到Python中的type。但是我们发现Py_TYPE(type) = Py_TYPE(base);这一行代码是把父类的ob_type设置成了当前类的ob_type,那么这一步的意义何在呢?我们使用Python来演示一下。
class MyType(type):
pass
class A(metaclass=MyType):
pass
class B(A):
pass
print(type(A)) # <class '__main__.MyType'>
print(type(B)) # <class '__main__.MyType'>我们看到B继承了A,而A的类型是MyType,那么B的类型也成了MyType。也就是说A类是由XX生成的,那么B在继承A的时候,B也会由XX生成,所以源码中的那一步就是用来做这件事情的。另外,这里之所以用XX代替,是因为Python中不仅仅type可以是元类,那些继承了type的子类也可以是元类。
而且如果你熟悉flask的话,你会发现flask源码里面就有类似于这样的操作:
class MyType(type):
def __new__(mcs, name, bases, attrs):
"""
关于第一个参数我们需要说一下, 对于一般的类来说这里应该是cls
但我们这里是元类, 所以用mcs代替
"""
# 我们额外设置一些属性吧, 关于元类我们后续会介绍
# 不过个人觉得既然要学习解释器, 那么首先至少应该在Python层面上知道用法
# 尽管不知道底层实现, 但至少使用方法应该知道
if name.startswith("G"):
# 如果类名以G开头, 那么就设置一些属性吧
attrs.update({"name": "夏色祭"})
return super().__new__(mcs, name, bases, attrs)
def with_metaclass(meta, bases=(object, )):
return meta("", bases, {})
class Girl(with_metaclass(MyType, (int,))):
pass
print(type(Girl)) # <class '__main__.MyType'>
print(getattr(Girl, "name")) # 夏色祭所以个位应该明白下面的代码是做什么的了,Python虚拟机就是将基类的metaclass设置为子类的metaclass。对于当前的PyType_Type来说,其metaclass就是object的metaclass,也是它自己,而在源码的PyBaseObject_Type中可以看到其ob_type是被设置成了PyType_Type的。
//设置type信息
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);既然继承了PyBaseObject_Type,那么便会首先初始化PyBaseObject_Type,我们下面来看看这个PyBaseObject_Type、Python中的object是怎么被初始化的。
处理基类列表
接下来,Python虚拟机会处理类型的基类列表,因为Python支持多重继承,所以每一个Python的类对象都会有一个基类、或者说父类列表。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
//获取tp_base中指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
...
...
...
//处理bases:基类列表
bases = type->tp_bases;
//如果bases为空
if (bases == NULL) {
//如果base也为空,说明这个类型对象一定是PyBaseObject_Type
//因为Python中任何类都继承自object,除了object自身
if (base == NULL)
//那么这时候bases就是个空元组,元素个数为0
bases = PyTuple_New(0);
else
//否则的话,就申请只有一个空间的元素,然后将PyBaseObject_Type塞进去
bases = PyTuple_Pack(1, base);
if (bases == NULL)
goto error;
//设置bases
type->tp_bases = bases;
}
}因此我们看到有两个属性,一个是tp_base,一个是tp_bases,我们看看这俩在Python中的区别。
class A:
pass
class B(A):
pass
class C:
pass
class D(B, C):
pass
print(D.__base__) # <class '__main__.B'>
print(D.__bases__) # (<class '__main__.B'>, <class '__main__.C'>)
print(C.__base__) # <class 'object'>
print(C.__bases__) # (<class 'object'>,)
print(B.__base__) # <class '__main__.A'>
print(B.__bases__) # (<class '__main__.A'>,)我们看到D同时继承多个类,那么tp_base就是先出现的那个基类,而tp_bases则是继承的所有基类,但是基类的基类是不会出现的,比如object。对于class B也是一样的。然后我们看看class C,因为C没有显式地继承任何类,那么tp_bases就是NULL,但是Python3中所有的类都默认继承了object,所以tp_base就是PyBaseObject_Type,那么就会把tp_base拷贝到tp_bases里面,因此也就出现了这个结果。
填充tp_dict
在设置完类型和基类之后,下面Python虚拟机就进入了激动人心的tp_dict的填充阶段,也就是设置属性字典,这是一个极其繁复、极其繁复、极其繁复的过程。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
//......
//......
//......
//初始化tp_dict
dict = type->tp_dict;
if (dict == NULL) {
dict = PyDict_New();
if (dict == NULL)
goto error;
type->tp_dict = dict;
}
//将与type相关的操作加入到tp_dict中
//注意: 这里的type是PyType_Ready的参数中的type, 所以它可以是Python中的<class 'type'>、也可以是<class 'int'>
if (add_operators(type) < 0)
goto error;
if (type->tp_methods != NULL) {
if (add_methods(type, type->tp_methods) < 0)
goto error;
}
if (type->tp_members != NULL) {
if (add_members(type, type->tp_members) < 0)
goto error;
}
if (type->tp_getset != NULL) {
if (add_getset(type, type->tp_getset) < 0)
goto error;
}
//.......
}在这个阶段,完成了将("__sub__", &long_sub)加入tp_dict的过程,里面的 add_operators 、 add_methods 、 add_members 、 add_getset 都是完成填充tp_dict的动作。那么这时候一个问题就出现了,Python是如何知道__add__和long_add之间存在关联的呢?其实这种关联显然是一开始就已经定好了的,而且存放在一个名为 slotdefs 的数组中。
slot与操作排序
在进入填充tp_dict的复杂操作之前,我们先来看一下Python中的一个概念:slot。在Python内部,slot可以视为表示PyTypeObject中定义的操作,一个操作对应一个slot,但是slot又不仅仅包含一个函数指针,它还包含一些其它信息,我们看看它的结构。在Python内部,slot是通过slotdef这个结构体来实现的。
//typeobject.c
typedef struct wrapperbase slotdef;
//descrobject.h
struct wrapperbase {
const char *name;
int offset;
void *function;
wrapperfunc wrapper;
const char *doc;
int flags;
PyObject *name_strobj;
}; //从定义上看, 我们发现slot不是一个PyObject在一个slot中,就存储着PyTypeObject中一种操作对应的各种信息,比如:int实例对象(PyLongObject)支持哪些行为,就看类型对象int(PyLong_Type)定义了哪些操作,而PyTypeObject对象中的一个操作就会有一个slot与之对应。slot里面的name就是操作对应的名称,比如字符串__sub__,offset则是操作的函数地址在PyHeapTypeObject中的偏移量,而function则指向一种名为slot function的函数。
Python中提供了多个宏来定义一个slot,其中最基本是TPSLOT和ETSLOT。
//typeobject.c
#define TPSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \
{NAME, offsetof(PyTypeObject, SLOT), (void *)(FUNCTION), WRAPPER, \
PyDoc_STR(DOC)}
#define ETSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \
{NAME, offsetof(PyHeapTypeObject, SLOT), (void *)(FUNCTION), WRAPPER, \
PyDoc_STR(DOC)}我们发现 PyHeapTypeObject 的第一个域就是 PyTypeObject ,因此可以发现TPSLOT计算出的也是 PyHeapTypeObject 的偏移量。
对于一个 PyTypeObject 来说,有的操作,比如long_add,其函数指针是在 PyNumberMethods 里面存放的,而 PyTypeObject 中却是通过一个tp_as_number指针指向另一个 PyNumberMethods 结构,因此这种情况是没办法计算出long_add在 PyTypeObject 中的偏移量的,只能计算出在 PyHeapTypeObject 中的偏移量,这种时候TPSLOT就失效了。
因此与long_add对应的slot必须是通过ETSLOT来定义的,但是我们说 PyHeapTypeObject 里面的offset表示的是基于 PyHeapTypeObject 得到的偏移量,而PyLong_Type却是一个 PyTypeObject 对象,那么通过这个偏移量显然无法得到PyLong_Type中为int准备的long_add,那~这个offset有什么用呢?
答案非常诡异,这个offset是用来对操作进行排序的。排序?我整个人都不好了,不过在理解为什么需要对操作进行排序之前,需要先看看Python底层预先定义的slot集合–slotdefs。
//typeobject.c
#define SQSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \
ETSLOT(NAME, as_sequence.SLOT, FUNCTION, WRAPPER, DOC)
static slotdef slotdefs[] = {
//不同操作名(__add__、__radd__)对象, 对应相同操作nb_add
//这个nb_add在PyLong_Type就是long_add,表示 +
BINSLOT("__add__", nb_add, slot_nb_add,
"+"),
RBINSLOT("__radd__", nb_add, slot_nb_add,
"+"),
BINSLOT("__sub__", nb_subtract, slot_nb_subtract,
"-"),
RBINSLOT("__rsub__", nb_subtract, slot_nb_subtract,
"-"),
BINSLOT("__mul__", nb_multiply, slot_nb_multiply,
"*"),
RBINSLOT("__rmul__", nb_multiply, slot_nb_multiply,
"*"),
//相同操作名(__getitem__)对应不同操作(mp_subscript、mp_ass_subscript)
MPSLOT("__getitem__", mp_subscript, slot_mp_subscript,
wrap_binaryfunc,
"__getitem__($self, key, /)\n--\n\nReturn self[key]."),
SQSLOT("__getitem__", sq_item, slot_sq_item, wrap_sq_item,
"__getitem__($self, key, /)\n--\n\nReturn self[key]."),
};其中BINSLOT,SQSLOT等这些宏实际上都是对ETSLOT的一个简单包装,并且在slotdefs中可以发现,操作名(比如__add__)和操作并不是一一对应的,存在多个操作对应同一个操作名、或者多个操作名对应同一个操作的情况,那么在填充tp_dict时,就会出现问题,比如对于__getitem__,在tp_dict中与其对应的是mp_subscript还是sq_item呢?
为了解决这个问题,就需要利用slot中的offset信息对slot(也就是操作)进行排序。回顾一下前面列出的 PyHeapTypeObject 的代码,它与一般的struct定义不同,其中定义中各个域的顺序是非常关键的,在顺序中隐含着操作优先级的问题。比如在 PyHeapTypeObject 中,PyMappingMethods 的位置在 PySequenceMethods 之前,mp_subscript是 PyMappingMethods 中的一个域:PyObject *,而sq_item又是 PySequenceMethods 中的的一个域:PyObject *,那么最终计算出的偏移量就存在如下关系:offset(mp_subscript) < offset(sq_item)。因此如果在一个PyTypeObject中,既定义了mp_subscript,又定义了sq_item,那么Python虚拟机将选择mp_subscript与__getitem__发生关系。
而对slotdefs的排序在init_slotdefs中完成:
//typeobject.c
static int slotdefs_initialized = 0;
static void
init_slotdefs(void)
{
slotdef *p;
//init_slotdefs只会进行一次
if (slotdefs_initialized)
return;
for (p = slotdefs; p->name; p++) {
/* Slots must be ordered by their offset in the PyHeapTypeObject. */
//注释也表名:slots一定要通过它们在PyHeapTypeObject中的offset进行排序
//而且是从小到大排
assert(!p[1].name || p->offset <= p[1].offset);
p->name_strobj = PyUnicode_InternFromString(p->name);
if (!p->name_strobj || !PyUnicode_CHECK_INTERNED(p->name_strobj))
Py_FatalError("Out of memory interning slotdef names");
}
//排完序之后将值赋为1, 这样的话下次执行的时候, 执行到上面的if时,由于条件为真就直接return了
slotdefs_initialized = 1;
}从slot到descriptor
在slot中,包含了很多关于一个操作的信息,但是很可惜,在tp_dict中,与”__getitem__“关联在一起的,一定不会是slot,因为它不是一个PyObject,无法将其指针放在dict对象中。当然如果再深入思考一下,会发现slot也无法被调用。因为slot不是一个PyObject,那么它就没有ob_type这个域,也就无从谈起什么tp_call了,所以slot是无论如也无法满足Python中的可调用这一条件的。前面我们说过,Python虚拟机在tp_dict找到__getitem__对应的操作后,会调用该操作,所以tp_dict中与__getitem__对应的只能是包装了slot的PyObject。在Python中,我们称之为descriptor。
在Python内部,存在多种descriptor,与descriptor相对应的是 PyWrapperDescrObject 。在后面的描述中也会直接使用descriptor代表 PyWrapperDescrObject 。一个descriptor包含一个slot,其创建是通过 PyDescr_NewWrapper 完成的。
//descrobject.h
#define PyDescr_COMMON PyDescrObject d_common
typedef struct {
PyObject_HEAD
PyTypeObject *d_type;
PyObject *d_name;
PyObject *d_qualname;
} PyDescrObject;
typedef struct {
PyDescr_COMMON;
struct wrapperbase *d_base;
void *d_wrapped; /* This can be any function pointer */
} PyWrapperDescrObject;
//descrobject.c
static PyDescrObject *
descr_new(PyTypeObject *descrtype, PyTypeObject *type, const char *name)
{
PyDescrObject *descr;
descr = (PyDescrObject *)PyType_GenericAlloc(descrtype, 0);
if (descr != NULL) {
Py_XINCREF(type);
descr->d_type = type;
descr->d_name = PyUnicode_InternFromString(name);
if (descr->d_name == NULL) {
Py_DECREF(descr);
descr = NULL;
}
else {
descr->d_qualname = NULL;
}
}
return descr;
}
PyObject *
PyDescr_NewWrapper(PyTypeObject *type, struct wrapperbase *base, void *wrapped)
{
PyWrapperDescrObject *descr;
descr = (PyWrapperDescrObject *)descr_new(&PyWrapperDescr_Type,
type, base->name);
if (descr != NULL) {
descr->d_base = base;
descr->d_wrapped = wrapped;
}
return (PyObject *)descr;
}Python内部的各种descriptor都将包含 PyDescr_COMMON ,其中的d_type被设置为PyDescr_NewWrapper的参数type,而d_wrapped则存放着最重要的信息:操作对应的函数指针,比如对于PyList_Type来说,其tp_dict["__getitem__"].d_wrapped就是&mp_subscript。而slot则被存放在了d_base中。
当然, PyWrapperDescrObject 里面的type是 PyWrapperDescr_Type ,其中的tp_call是 wrapperdescr_call ,当Python虚拟机调用一个descriptor时,也就会调用 wrapperdescr_call 。对于descriptor的调用过程,我们将在后面详细介绍。
print(int.__sub__) # <slot wrapper '__sub__' of 'int' objects>
print(str.__add__) # <slot wrapper '__add__' of 'str' objects>
print(str.__getitem__) # <slot wrapper '__getitem__' of 'str' objects>我们看到它们都是一个slot wrapper,也就是对slot包装之后的descriptor(描述符)。
建立联系
排序后的结果仍然存放在slotdefs中,python虚拟机这下就可以从头到尾遍历slotdefs,基于每一个slot建立一个descriptor,然后在tp_dict中建立从操作名到descriptor的关联,这个过程是在add_operators中完成的。
static int
add_operators(PyTypeObject *type)
{
PyObject *dict = type->tp_dict;
slotdef *p;
PyObject *descr;
void **ptr;
//对slotdefs进行排序
init_slotdefs();
for (p = slotdefs; p->name; p++) {
//如果slot中没有指定wrapper,则无需处理
if (p->wrapper == NULL)
continue;
//获得slot对应的操作在PyTypeObject中的函数指针
ptr = slotptr(type, p->offset);
if (!ptr || !*ptr)
continue;
//如果tp_dict中已经存在操作名,则放弃
if (PyDict_GetItemWithError(dict, p->name_strobj))
continue;
if (PyErr_Occurred()) {
return -1;
}
if (*ptr == (void *)PyObject_HashNotImplemented) {
/* Classes may prevent the inheritance of the tp_hash
slot by storing PyObject_HashNotImplemented in it. Make it
visible as a None value for the __hash__ attribute. */
if (PyDict_SetItem(dict, p->name_strobj, Py_None) < 0)
return -1;
}
else {
//创建descriptor
descr = PyDescr_NewWrapper(type, p, *ptr);
if (descr == NULL)
return -1;
//将(操作名,descriptor)放入tp_dict中
if (PyDict_SetItem(dict, p->name_strobj, descr) < 0) {
Py_DECREF(descr);
return -1;
}
Py_DECREF(descr);
}
}
if (type->tp_new != NULL) {
if (add_tp_new_wrapper(type) < 0)
return -1;
}
return 0;
}在add_operators中,首先调用前面剖析过的init_slotdefs对操作进行排序,然后遍历排序完成后的slotdefs结构体数组,对其中的每一个slot(slotdef),通过slotptr获得该slot对应的操作在PyTypeObject中的函数指针,,并接着创建descriptor,在tp_dict中建立从操作名(slotdef.name_strobj)到操作(descriptor)的关联。
但是需要注意的是,在创建descriptor之前,Python虚拟机会检查在tp_dict中操作名是否存在,如果存在了,则不会再次建立从操作名到操作的关联。不过也正是这种检查机制与排序机制相结合,Python虚拟机在能在拥有相同操作名的多个操作中选择优先级最高的操作。
在add_operators中,上面的动作都很简单、直观,而最难的动作隐藏在slotptr这个函数当中。它的功能是完成从slot到slot对应操作的真实函数指针的转换。我们知道,在slot中存放着用来操作的offset,但不幸的是,这个offset是相对于 PyHeapTypeObject 的偏移,而操作的真实函数指针却是在 PyTypeObject 中指定的,而且 PyTypeObject 和 PyHeapTypeObject 不是同构的,因为 PyHeapTypeObject 中包含了 PyNumberMethods 结构体,但 PyTypeObject 只包含了 PyNumberMethods * 指针。所以slot中存储的关于操作的offset对 PyTypeObject 来说,不能直接用,必须通过转换。
举个栗子,假如说调用
slotptr(&PyList_Type, offset(PyHeapTypeObject, mp_subscript)),首先判断这个偏移量大于offset(PyHeapTypeObject, as_mapping),所以会先从PyTypeObject对象中获得as_mapping指针p,然后在p的基础上进行偏移就可以得到实际的函数地址。所以偏移量delta为:
offset(PyHeapTypeObject, mp_subscript) - offset(PyHeapTypeObject, as_mapping)。
而这个复杂的过程就在slotptr中完成:
static void **
slotptr(PyTypeObject *type, int ioffset)
{
char *ptr;
long offset = ioffset;
/* Note: this depends on the order of the members of PyHeapTypeObject! */
assert(offset >= 0);
assert((size_t)offset < offsetof(PyHeapTypeObject, as_buffer));
//从PyHeapTypeObject中排在后面的PySequenceMethods开始判断,然后向前,依次判断PyMappingMethods和PyNumberMethods呢。
/*
为什么要这么做呢?假设我们首先从PyNumberMethods开始判断
如果一个操作的offset大于在PyHeapTypeObject中的as_numbers在PyNumberMethods的偏移量,那么我们还是没办法确认这个操作到底是属于谁的。只有从后往前进行判断,才能解决这个问题。
*/
if ((size_t)offset >= offsetof(PyHeapTypeObject, as_sequence)) {
ptr = (char *)type->tp_as_sequence;
offset -= offsetof(PyHeapTypeObject, as_sequence);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_mapping)) {
ptr = (char *)type->tp_as_mapping;
offset -= offsetof(PyHeapTypeObject, as_mapping);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_number)) {
ptr = (char *)type->tp_as_number;
offset -= offsetof(PyHeapTypeObject, as_number);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_async)) {
ptr = (char *)type->tp_as_async;
offset -= offsetof(PyHeapTypeObject, as_async);
}
else {
ptr = (char *)type;
}
if (ptr != NULL)
ptr += offset;
return (void **)ptr;
}好了,我想到现在我们应该能够摸清楚Python在改造PyTypeObject对象时对tp_dict做了什么了,我们以PyList_Type举例说明:

在add_operators完成之后,PyList_Type如图所示。从PyList_Type.tp_as_mapping中延伸出去的部分是在编译时就已经确定好了的,而从tp_dict中延伸出去的部分则是在Python运行时环境初始化的时候才建立的。
另外, PyType_Ready 在通过add_operators添加了 PyTypeObject 对象中定义的一些operator后,还会通过add_methods、add_numbers和add_getsets添加 PyTypeObject 中定义的tp_methods、tp_members和tp_getset函数集。这些过程和add_operators类似,不过最后添加到tp_dict中descriptor就不再是 PyWrapperDescrObject ,而分别是 PyMethodDescrObject 、PyMemberDescrObject 、 PyGetSetDescrObject 。
print(str.__add__) # <slot wrapper '__add__' of 'str' objects>
print(list.__add__) # <slot wrapper '__add__' of 'list' objects>
print(str.__getitem__) # <slot wrapper '__getitem__' of 'str' objects>
print(list.__getitem__) # <method '__getitem__' of 'list' objects>
# 我们看到对于list的__getitem__来说, 就不再是PyWrapperDescrObject(slot wrapper)了
# 而是一个PyMethodDescrObject从目前来看,基本上算是解析完了,但是还有一点:
class A(list):
def __repr__(self):
return "xxx"
a = A()
print(a) # xxx显然当我们print(a)的时候,应该调用A.tp_repr函数,对照PyList_Type的布局,应该调用list_repr这个函数,然而事实却并非如此,Python虚拟机调用的是我们在A中重写的__repr__方法。这意味着Python在初始化A的时候,对tp_repr进行了特殊处理。为什么Python虚拟机会知道要对tp_repr进行特殊处理呢?当然肯定有人会说:这是因为我们重写了__repr__方法啊,确实如此,但这是Python层面上的,在底层的话,答案还是在slot身上。
//typeobject.c
static slotdef slotdefs[] = {
...
TPSLOT("__repr__", tp_repr, slot_tp_repr, wrap_unaryfunc,
"__repr__($self, /)\n--\n\nReturn repr(self)."),
...
} Python虚拟机在初始化A时,会检查A的tp_dict中是否存在__repr__,在后面剖析自定义class对象的创建时会看到,因为在定义class A的时候,重写了__repr__这个操作。所以在A.tp_dict中,__repr__一开始就会存在,Python虚拟机会检测到,然后会根据__repr__对应的slot顺藤摸瓜,找到tp_repr,并且将这个函数指针替换为slot中指定的&slot_tp_repr。所以当后来虚拟机找A.tp_repr的时候,实际上找的是slot_tp_repr。
//typeobject.c
static PyObject *
slot_tp_repr(PyObject *self)
{
PyObject *func, *res;
_Py_IDENTIFIER(__repr__);
int unbound;
//查找__repr__属性
func = lookup_maybe_method(self, &PyId___repr__, &unbound);
if (func != NULL) {
//调用__repr__对应的对象
res = call_unbound_noarg(unbound, func, self);
Py_DECREF(func);
return res;
}
PyErr_Clear();
return PyUnicode_FromFormat("<%s object at %p>",
Py_TYPE(self)->tp_name, self);
}在slot_tp_repr中,会寻找__repr__属性对应的对象,正好就会找到在A中重写的函数,后面会看到,这个对象实际上就一个PyFunctionObject对象。这样一来,就完成了对默认的list的repr行为的替换。所以对于A来说,内存布局就是下面这样。

当然这仅仅是针对于__repr__,对于其他的操作还是会指向PyList_Type中指定的函数,比如tp_iter还是会指向list_iter。因为我们的类A继承list,所以如果某个函数在A里面没有的话,那么会 从PyList_Type中寻找。
对于A来说,这个变化是在 fixup_slot_dispatchers 这个函数中完成的,对于内建对象则不会进行此操作,因为内建对象是被静态初始化的,它不允许属性的动态设置。
//typeobject.c
static void
fixup_slot_dispatchers(PyTypeObject *type)
{
slotdef *p;
init_slotdefs();
for (p = slotdefs; p->name; )
p = update_one_slot(type, p);
}确定MRO
MRO,即method resolve order,说白了就是类继承之后、属性或方法的查找顺序。如果Python是单继承的话,那么这就不是问题了,直接一层一层网上找就可以了。但是Python是支持多继承的,那么在多继承时,继承的顺序就成为了一个必须考虑的问题。
class A:
def foo(self):
print("A")
class B(A):
def foo(self):
print("B")
class C(A):
def foo(self):
print("C")
self.bar()
def bar(self):
print("bar C")
class D(C, B):
def bar(self):
print("bar D")
d = D()
d.foo()
"""
C
bar D
"""首先我们看到,打印的是C,说明调用的是C的foo函数,这说明把C写在前面,会调用C的方法。但是下面打印了bar D,这是因为C里面的self,实际上是D的实例对象。D在找不到foo函数的时候,会到父类里面找,但是同时也会将self传递过去,所以调用self.bar的时候,还是会先到D里面找,如果找不到再去父类里面找。
在底层则是先在PyType_Ready中通过mro_internal确定mro的顺序,Python虚拟机将创建一个PyTupleObject对象,里面存放一组类对象,这些类对象的顺序就是虚拟机确定的mro的顺序,最终这个PyTuple对象会被保存在PyTypeObject.tp_mro中。
由于mro_internal内部的实现机制相当复杂,所以我们将会只从python的代码层面来理解。首先我们说python早期有经典类和新式类两种类,现在则只存在新式类。而经典类的类搜索方式采用的是深度优先,而新式类则是广度优先(当然现在用的是新的算法,具体什么算法后面说,暂时理解为广度优先即可),举个例子:
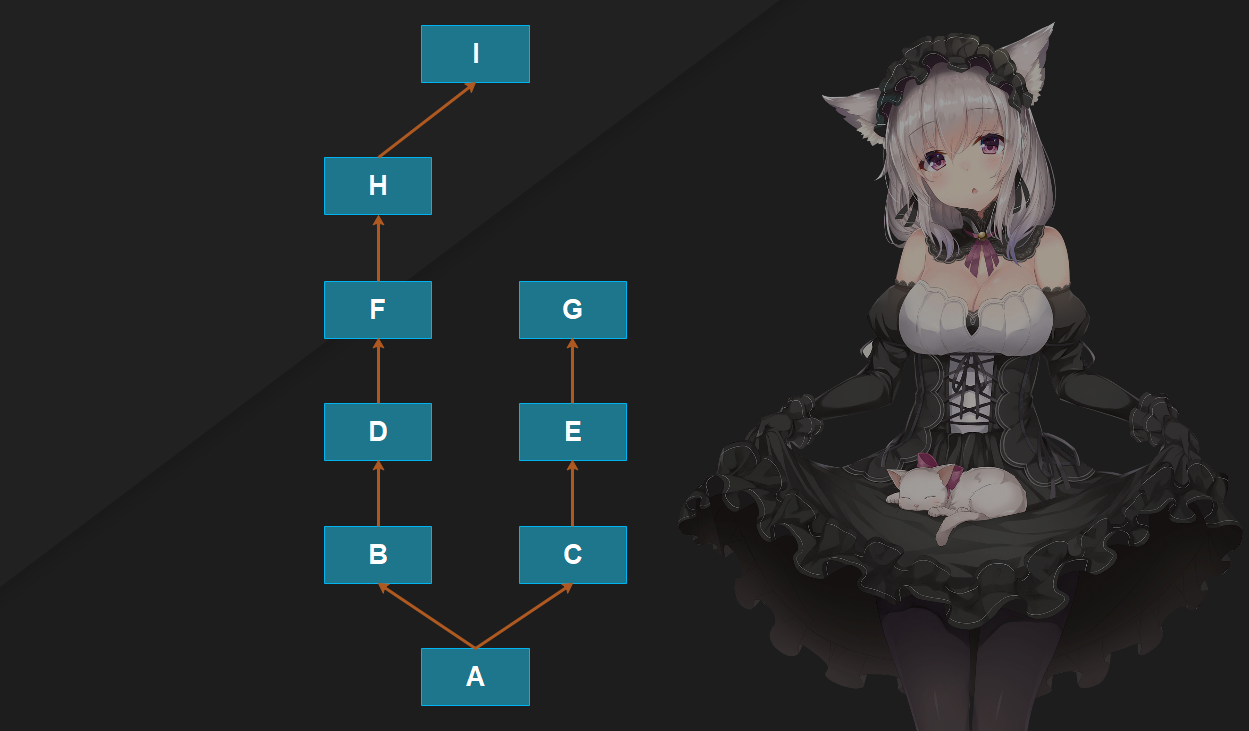
图中的箭头表示继承关系,比如:A继承B和C、B继承D、C继承E。
对于上图来说,经典类和新式类的查找方式是一样的:先从A找到I,再从C找到G。对于上图这种继承结构,经典类和新式类是一样的,至于两边是否一样多则不重要。我们实际演示一下,由于经典类只在Python2中存在,所以下面我们演示新式类。
# 这里是python3.8 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (), {})
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.F'>
<class '__main__.H'>
<class '__main__.I'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.G'>
<class 'object'>
"""对于A继承两个类,这个两个类分别继续继承,如果最终没有继承公共的类(暂时先忽略object),那么经典类和新式类是一样的。像这种泾渭分明、各自继承各自的,都是先一条路找到黑,然后再去另外一条路去找。
但如果是下面这种,最终分久必合、两者最终又继承了同一个类,那么经典类还是跟以前一样,按照每一条路都走到黑的方式。但是对于新式类,则是先从A找到H,而I这个两边最终继承的类不找了,然后从C找到I,也就是在另一条路找到头。
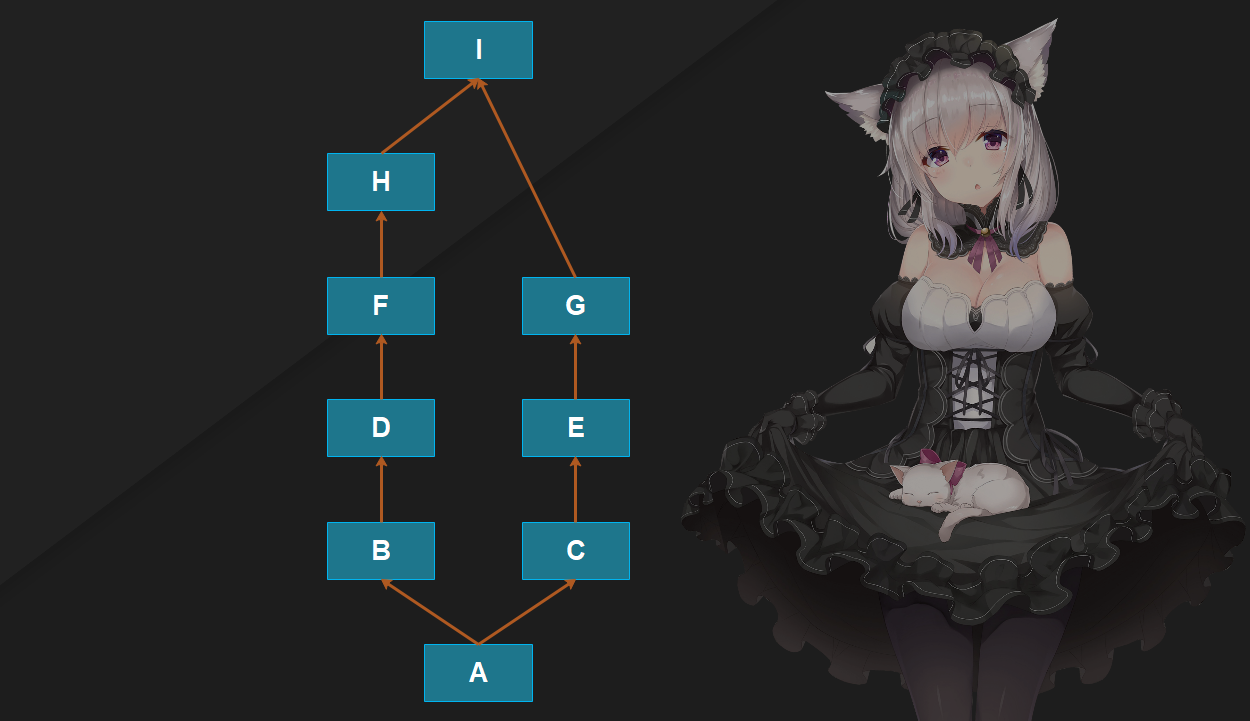
# 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (I,), {}) # 这里让G继承I
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.F'>
<class '__main__.H'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.G'>
<class '__main__.I'>
<class 'object'>
"""因此对于最下面的类继承两个类,然后继承的两个类再次继承的时候,向上只继承一个类,对于这种模式,那么结论、也就是mro顺序就是我们上面分析的那样。不过对新式类来说,因为所有类默认都是继承object,所以第一张图中,即使我们没画完,但是也能想到,两条泾渭分明的继承链的上方最终应该都指向object。那么我们依旧可以用刚才的理论来解释,在第一条继承链中找到object的前一个类不找了,然后在第二条继承链中一直找到object。
但是Python的多继承远比我们想象的要复杂,原因就在于可以任意继承,如果B和C再分别继承两个类呢?那么我们这里的线路就又要多出两条了,不过既然要追求刺激,就贯彻到底喽。但是下面我们就只会介绍新式类了,经典类了解一下就可以了。
另外我们之前说新式类采用的是广度优先,但是实际上这样有一个问题:
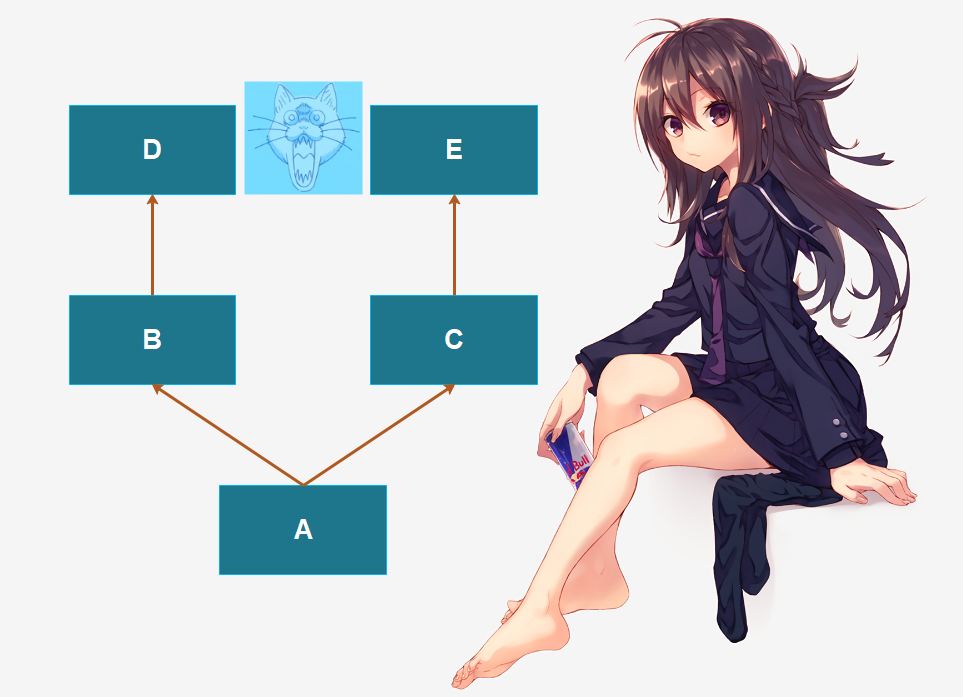
假设我们调用A的foo方法,但是A里面没有,那么理所应当会去B里面找,但是B里面也没有,而C和D里面有,那么这个时候是去C里面找还是去D里面找呢?根据我们之前的结论,显然是去D里面找,可如果按照广度优先的逻辑来说,那么应该是去C里面找啊。所以广度优先理论在这里就不适用了,因为B继承了D,而B和C并没有直接关系,我们应该把B和D看成一个整体。因此Python中的广度优先实际上是采用了一种叫做C3的算法。
这个C3算法比较复杂(其实也不算复杂),只不过我个人总结出一个更加好记的结论,如下:
当沿着一条继承链寻找类时,默认会该继承链一直找下去,但如果发现某个类出现在了另一条继承链当中,那么当前的继承链的搜索就会结束,然后在”最开始”出现分歧的地方转向下一条继承链的搜索。
这是我个人总结的,或许光看字面意思的话会比较难理解,但是通过例子就能明白了。
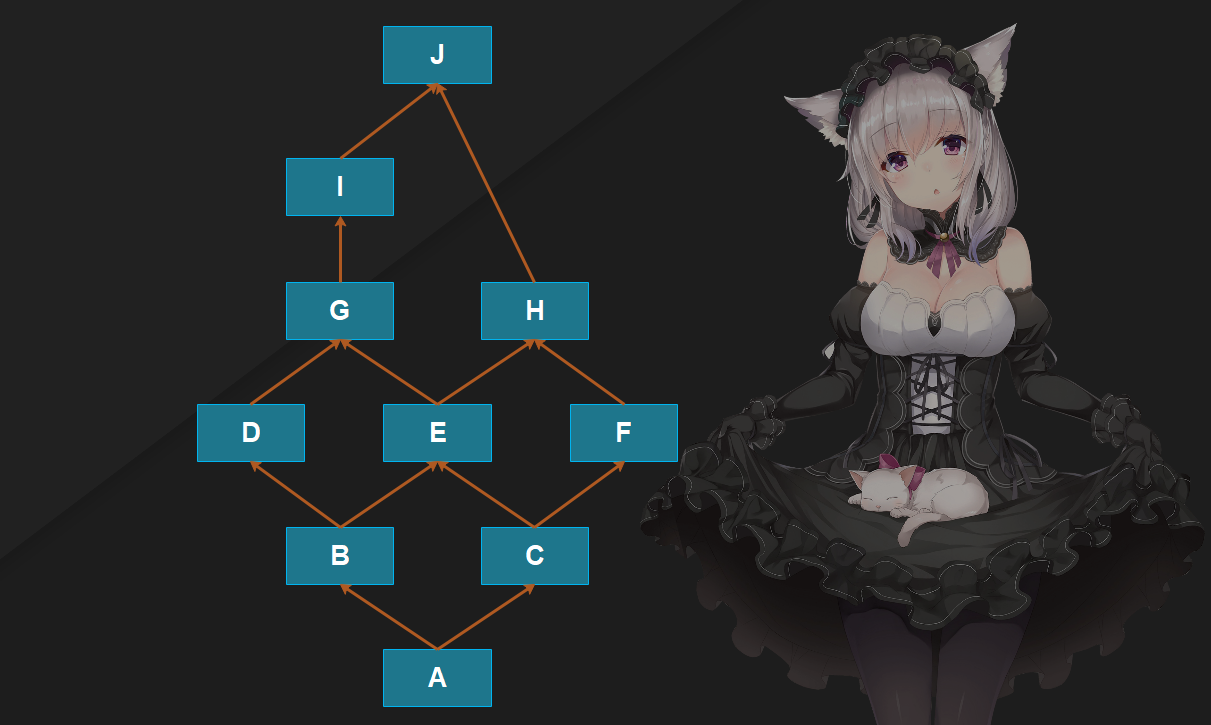
这个箭头表示继承关系,继承顺序是从左到右,比如这里的A就相当于class A(B, C),下面我们来从头到尾分析一下。
1. 首先最开始的顺序是A, 如果我们获取A的mro的话;2. 然后A继承B和C, 由于是两条路, 因此我们说A这里就是一个分歧点。但是由于B在前, 所以接下来是B, 所以现在mro的顺序是A B;3. 但是B这里也出现了分歧点, 不过不用管, 因为我们说会沿着继承链不断往下搜索, 现在mro的顺序是A B D;4. 然后从D开始寻找, 这里注意了, 按理说会找G的, 但是G不止被一个类继承, 也就是意味着沿着当前的继承链查找G时, G还出现在了其它的继承链当中。怎么办?显然要回到最初的分歧点, 转向下一条继承链的搜索;5. 最初的分歧点是A, 那么该去找C了, 现在mro的顺序就是A B D C;6. 注意C这里出现了分歧点, 而A的两条分支已经结束了, 所以现在C就是最初的分歧点了。而C继承自E和F, 显然要搜索E, 那么此时mro的顺序就是A B D C E;7. 然后从E开始搜索, 显然要搜索G, 此时mro顺序是A B D C E G;8. 从G要搜索I, 此时mro顺序是A B D C E G I;9. 从I开始搜索谁呢?由于J出现在了其它的继承链中, 那么要回到最初分歧的地方, 也就是C, 那么下面显然要找F, 此时mro顺序是A B D C E G I F;10. F只继承了H, 那么肯定要找H, 此时mro顺序是 A B D C E G I F H;11. H显然只能找J了, 因此最终A的mro顺序就是A B D C E G I F H J object;J = type(“J”, (object, ), {})
I = type(“I”, (J, ), {})
H = type(“H”, (J, ), {})
G = type(“G”, (I, ), {})
F = type(“F”, (H, ), {})
E = type(“E”, (G, H), {})
D = type(“D”, (G, ), {})
C = type(“C”, (E, F), {})
B = type(“B”, (D, E), {})
A = type(“A”, (B, C), {})A B D C E G I F H J
for _ in A.mro:
print(_)“””
<class ‘main.A’>
<class ‘main.B’>
<class ‘main.D’>
<class ‘main.C’>
<class ‘main.E’>
<class ‘main.G’>
<class ‘main.I’>
<class ‘main.F’>
<class ‘main.H’>
<class ‘main.J’>
<class ‘object’>
“””
我们再看一个复杂的例子感受一下:

看起来很花里胡哨的,但其实很简单,就按照之前说的那个结论不断推导下去即可。
1. 首先是A, A继承B1、B2、B3, 会先走B1, 此时mro是A B1, 注意现在A是分歧点;2. 从B1本来该找C1, 但是C1还被其他类继承, 也就是出现在了其它的继承链当中, 因此要回到最初分歧点A, 从下一条继承链开始找, 显然要找B2, 此时mro就是A B1 B2;3. 从B2开始, 显然要找C1, 此时mro顺序就是A B1 B2 C1;4. 从C1开始, 显然要找D1, 因为D1只被C1继承, 所以它没有出现在另一条继承链当中, 因此此时mro顺序是A B1 B2 C1 D1;5. 从D1显然不会找E的, 咋办? 回到最初的分歧点, 注意这里显然还是A, 因为A的分支还没有走完。显然此时要走B3, 那么mro顺序就是A B1 B2 C1 D1 B3;6. 从B3开始找, 显然要找C2, 注意: A的分支已经走完, 此时B3就成了新的最初分歧点。现在mro顺序是A B1 B2 C1 D1 B3 C2;7. C2会找D2吗? 显然不会, 因为它还被C3继承, 所以它出现在了其他的继承链中。所以要回到最初分歧点, 这里是B3, 显然下面要找C3, 另外由于B3的分支也已经走完, 所以现在C3就成了新的最初分歧点。此时mro顺序是A B1 B2 C1 D1 B3 C2 C3;8. 从C3开始, 显然要找D2, 此时mro顺序是A B1 B2 C1 D1 B3 C2 C3 D2;9. 但是D2不会找E, 因此回到最初分歧点C3, 下面就找D3, 然后显然只能再找E了, 显然最终mro顺序A B1 B2 C1 D1 B3 C2 C3 D2 D3 E object;E = type(“E”, (), {})
D1 = type(“D1”, (E,), {})
D2 = type(“D2”, (E,), {})
D3 = type(“D3”, (E,), {})
C1 = type(“C1”, (D1, D2), {})
C2 = type(“C2”, (D2,), {})
C3 = type(“C3”, (D2, D3), {})
B1 = type(“B1”, (C1,), {})
B2 = type(“B2”, (C1, C2), {})
B3 = type(“B3”, (C2, C3), {})
A = type(“A”, (B1, B2, B3), {})for _ in A.mro:
print(_)“””
<class ‘main.A’>
<class ‘main.B1’>
<class ‘main.B2’>
<class ‘main.C1’>
<class ‘main.D1’>
<class ‘main.B3’>
<class ‘main.C2’>
<class ‘main.C3’>
<class ‘main.D2’>
<class ‘main.D3’>
<class ‘main.E’>
<class ‘object’>
“””
因此Python的多继承并没有我们想象的那么复杂,当然底层源码我们就不再看了,这个东西分析起来没什么太大必要,有兴趣可以自己去看一下。个人觉得,关于多继承从目前这个层面上来理解已经足够了。
不过需要注意的是,在执行父类函数时传入的self参数,这一点是很多初学者容易犯的错误。
class A:
def foo(self):
print("A: foo")
self.bar()
def bar(self):
print("A: bar")
class B:
def bar(self):
print("B: bar")
class C(A, B):
def bar(self):
print("C: bar")
C().foo()
"""
A: foo
C: bar
"""首先C的实例对象在调用foo的时候,首先会去C里面查找,但是C没有,所以按照mro顺序会去A里面找。而A里面存在,所以调用,但是:调用时传递的self是C的实例对象,因为是C的实例对象调用的。所以里面的self.bar,这个self还是C的实例对象,那么调用bar的时候,会去哪里找呢?显然还是从C里面找,所以 self.bar() 的时候打印的是”C: bar”,而不是”A: bar”。
同理再来看看一个关于super的栗子:
class A:
def foo(self):
super(A, self).foo()
class B:
def foo(self):
print("B: foo")
class C(A, B):
pass
try:
A().foo()
except Exception as e:
print(e) # 'super' object has no attribute 'foo'
# 首先A的父类是object, 所以super(A, self).foo()的时候回去执行object的foo
# 但是object没有foo, 所以报错了, 报错信息中的'super'指的就是A的父类
# 但是, 是的, 我要说但是了
C().foo() # B: foo
"""
如果是C()调用foo的话, 最终却执行了B的foo函数, 这是什么原因呢?
首先C里面里面没有foo, 那么会去执行A的foo, 但是执行时候的self是C的实例对象, super里面的self也是C里面的self
然后我们知道对于C而言, 其mro是 C、A、B、object
所以super(A, self).foo() 就表示: 沿着继承链 C、A、B、object的顺序去找foo函数
但是super里面有一个A, 表示不要从头开始找, 而是从A的后面开始找, 所以下一个就找到B了
"""所以说super不一定就是父类,而是要看里面的self是谁。总之:super(xxx, self)一定是type(self)对应的mro中,xxx的下一个类。
继承基类操作
python虚拟机确定了mro顺序列表之后,就会遍历mro列表(第一个类对象会是其自身,比如A.__mro__的第一个元素就是A本身,所以遍历是从第二项开始的)。在mro列表中实际上存储的就是类对象的所有直接基类、间接基类,Python虚拟机会将自身没有、但是基类(注意:包括间接基类,比如基类的基类)中存在的操作拷贝到该类当中,从而完成对基类操作的继承动作。
而这个继承操作的动作是发生在inherit_slots中
//typeobject.c
int
PyType_Ready(PyTypeObject *type)
{
//...
//...
bases = type->tp_mro;
assert(bases != NULL);
assert(PyTuple_Check(bases));
n = PyTuple_GET_SIZE(bases);
for (i = 1; i < n; i++) {
PyObject *b = PyTuple_GET_ITEM(bases, i);
if (PyType_Check(b))
inherit_slots(type, (PyTypeObject *)b);
}
...
...
}在inherit_slots中会拷贝相当多的操作,这里就拿nb_add(整型则对应long_add)来举个栗子:
static void
inherit_slots(PyTypeObject *type, PyTypeObject *base)
{
PyTypeObject *basebase;
#undef SLOTDEFINED
#undef COPYSLOT
#undef COPYNUM
#undef COPYSEQ
#undef COPYMAP
#undef COPYBUF
#define SLOTDEFINED(SLOT) \
(base->SLOT != 0 && \
(basebase == NULL || base->SLOT != basebase->SLOT))
#define COPYSLOT(SLOT) \
if (!type->SLOT && SLOTDEFINED(SLOT)) type->SLOT = base->SLOT
#define COPYASYNC(SLOT) COPYSLOT(tp_as_async->SLOT)
#define COPYNUM(SLOT) COPYSLOT(tp_as_number->SLOT)
#define COPYSEQ(SLOT) COPYSLOT(tp_as_sequence->SLOT)
#define COPYMAP(SLOT) COPYSLOT(tp_as_mapping->SLOT)
#define COPYBUF(SLOT) COPYSLOT(tp_as_buffer->SLOT)
/* This won't inherit indirect slots (from tp_as_number etc.)
if type doesn't provide the space. */
if (type->tp_as_number != NULL && base->tp_as_number != NULL) {
basebase = base->tp_base;
if (basebase->tp_as_number == NULL)
basebase = NULL;
COPYNUM(nb_add);
COPYNUM(nb_subtract);
COPYNUM(nb_multiply);
COPYNUM(nb_remainder);
COPYNUM(nb_divmod);
COPYNUM(nb_power);
COPYNUM(nb_negative);
COPYNUM(nb_positive);
COPYNUM(nb_absolute);
COPYNUM(nb_bool);
COPYNUM(nb_invert);
COPYNUM(nb_lshift);
COPYNUM(nb_rshift);
COPYNUM(nb_and);
COPYNUM(nb_xor);
COPYNUM(nb_or);
COPYNUM(nb_int);
COPYNUM(nb_float);
COPYNUM(nb_inplace_add);
COPYNUM(nb_inplace_subtract);
COPYNUM(nb_inplace_multiply);
COPYNUM(nb_inplace_remainder);
COPYNUM(nb_inplace_power);
COPYNUM(nb_inplace_lshift);
COPYNUM(nb_inplace_rshift);
COPYNUM(nb_inplace_and);
COPYNUM(nb_inplace_xor);
COPYNUM(nb_inplace_or);
COPYNUM(nb_true_divide);
COPYNUM(nb_floor_divide);
COPYNUM(nb_inplace_true_divide);
COPYNUM(nb_inplace_floor_divide);
COPYNUM(nb_index);
COPYNUM(nb_matrix_multiply);
COPYNUM(nb_inplace_matrix_multiply);
}
//......
//......我们在里面看到很多熟悉的东西,如果你常用魔法方法的话。而且我们知道PyBool_Type中并没有设置nb_add,但是PyLong_Type中却设置了nb_add操作,而bool继承int。所以对布尔类型是可以直接进行运算的,当然和整型、浮点型运算也是可以的。所以在numpy中,判断一个数组中多少个满足条件的元素,可以使用numpy提供的机制进行比较,会得到一个同样长度的数组,里面的每一个元素为是否满足条件所对应的布尔值。然后直接通过sum运算即可,因为运算的时候,True会被解释成1,False会被解释成0。
import numpy as np
arr = np.array([2, 4, 7, 3, 5])
print(arr > 4) # [False False True False True]
print(sum(arr > 4)) # 2
print(2.2 + True) # 3.2所以在python中,整型是可以和布尔类型进行运算的,看似不可思议,但又在情理之中。
填充基类中的子类列表
到这里,PyType_Ready还剩下最后一个重要的动作了:设置基类中的子类列表。在每一个PyTypeObject中,有一个tp_subclasses,这个东西在PyType_Ready完成之后,将会是一个list对象。其中存放着所有直接继承自类的类对象,PyType_Ready是通过调用add_subclass完成向这个tp_subclasses中填充子类的动作。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
//填充基类的子类列表
bases = type->tp_bases;
n = PyTuple_GET_SIZE(bases);
for (i = 0; i < n; i++) {
PyObject *b = PyTuple_GET_ITEM(bases, i);
if (PyType_Check(b) &&
add_subclass((PyTypeObject *)b, type) < 0)
goto error;
}
}
print(object.__subclasses__())
# [<class 'type'>, <class 'weakref'>, <class 'weakcallableproxy'>,
# <class 'weakproxy'>, <class 'int'>, <class 'bytearray'>, <class 'bytes'>,
# <class 'list'>, <class 'NoneType'>, <class 'NotImplementedType'>,
# <class 'traceback'>, <class 'super'>, ... ... ...果然,python里面的object不愧是万物之父,这么多的内建对象都是继承自object的。到了这里,我们才算是完整的剖析了PyType_Ready的动作,可以看到,python虚拟机对python的内建对象对应的PyTypeObject进行了多种繁杂的改造工作,可以包括以下几部分:
设置type信息,基类及基类列表;填充tp_dict;确定mro列表;基于mro列表从基类继承操作;设置基类的子类列表;
不同的类型,有些操作也会有一些不同的行为,但整体是一致的。因此具体某个特定类型,可以自己跟踪PyType_Ready的操作。
小结
我们看到类的属性查找虽然看起来简单,但是底层实现起来还是很复杂的。当然关于自定义的类是如何构建的,我们将在下一篇博客中进行剖析。
