下面我们来说一下Python中线程的创建,我们知道在创建多线程的时候会使用threading这个标准库,这个库是以一个py文件存在的形式存在的,不过这个模块依赖于_thread模块,我们来看看它长什么样子。
Tags:
via Pocket https://ift.tt/3dfcfWR original site
February 16, 2021 at 10:15PM
Comments
from: github-actions[bot] on: 3/3/2021
《深度剖析CPython解释器》26. 解密Python中的多线程(第二部分):源码剖析Python线程的创建、销毁、调度,以及GIL的实现原理 - 古明地盆 - 博客园
《深度剖析CPython解释器》26. 解密Python中的多线程(第二部分):源码剖析Python线程的创建、销毁、调度,以及GIL的实现原理
初见Python的_thread模块
下面我们来说一下Python中线程的创建,我们知道在创建多线程的时候会使用threading这个标准库,这个库是以一个py文件存在的形式存在的,不过这个模块依赖于_thread模块,我们来看看它长什么样子。
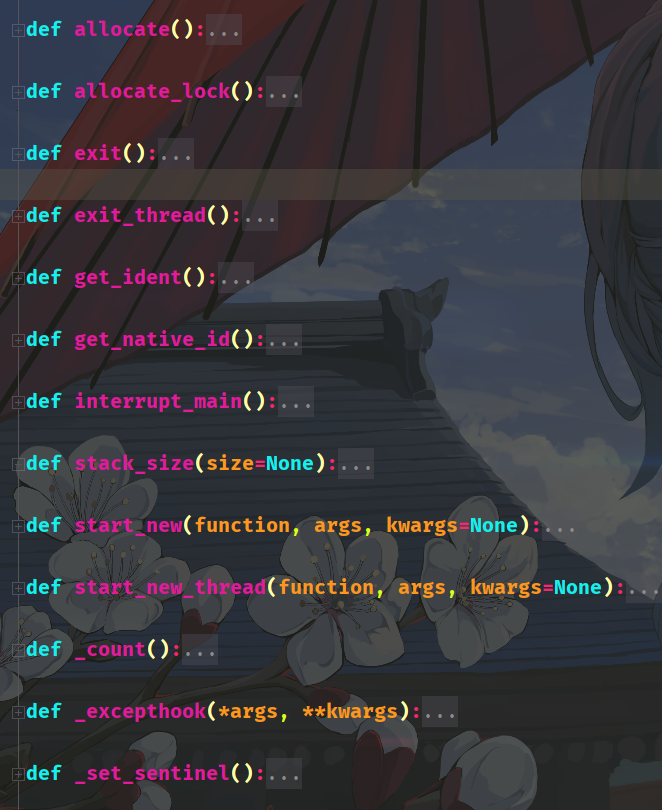
_thread是真正用来创建线程的模块,这个模块是由C编写,内嵌在解释器里面。我们可以import调用,但是在Python安装目录里面则是看不到的。像这种底层由C编写、内嵌在解释器里面的模块,以及那些无法使用文本打开的pyd文件,pycharm都会给你做一个抽象,并且把注释给你写好。
记得我们之前说过Python源码中的Modules目录,这个目录里面存放了大量使用C编写的模块,我们在编译完Python之后就,这些模块就内嵌在解释器里面了。而这些模块都是针对那些性能要求比较高的,而要求不高的则由Python编写,存放在Lib目录下。像我们平时调用random、collections、threading,其实它们背后会调用_random、_collections、_thread。再比如我们使用的re模块,真正用来做正则匹配的逻辑实际上位于 Modules/_sre.c 里面。
说了这么多,只是为引出_thread是在Modules里面。玛德,前戏真长啊。Python中 _thread 的底层实现是在 _threadmodule.c中,我们来看看它都提供了哪些接口。
static PyMethodDef thread_methods[] = {
{"start_new_thread", (PyCFunction)thread_PyThread_start_new_thread,
METH_VARARGS, start_new_doc},
{"start_new", (PyCFunction)thread_PyThread_start_new_thread,
METH_VARARGS, start_new_doc},
{"allocate_lock", thread_PyThread_allocate_lock,
METH_NOARGS, allocate_doc},
{"allocate", thread_PyThread_allocate_lock,
METH_NOARGS, allocate_doc},
{"exit_thread", thread_PyThread_exit_thread,
METH_NOARGS, exit_doc},
{"exit", thread_PyThread_exit_thread,
METH_NOARGS, exit_doc},
{"interrupt_main", thread_PyThread_interrupt_main,
METH_NOARGS, interrupt_doc},
{"get_ident", thread_get_ident,
METH_NOARGS, get_ident_doc},
#ifdef PY_HAVE_THREAD_NATIVE_ID
{"get_native_id", thread_get_native_id,
METH_NOARGS, get_native_id_doc},
#endif
{"_count", thread__count,
METH_NOARGS, _count_doc},
{"stack_size", (PyCFunction)thread_stack_size,
METH_VARARGS, stack_size_doc},
{"_set_sentinel", thread__set_sentinel,
METH_NOARGS, _set_sentinel_doc},
{"_excepthook", thread_excepthook,
METH_O, excepthook_doc},
{NULL, NULL} /* sentinel */
};我们看到第一个 start_new_thread 和第二个 start_new ,发现它们都对应 thread_PyThread_start_new_thread 这个函数,这些接口和_thread.py中对应的是一致的。
线程的创建
当我们使用threading模块创建一个线程的时候,threading会调用_thread模块来创建,而在_thread中显然是通过里面 start_new_thread 对应的 thread_PyThread_start_new_thread 来创建,下面我们就来看看这个函数。
//Modules/_threadmodule.c
static PyObject *
thread_PyThread_start_new_thread(PyObject *self, PyObject *fargs)
{
PyObject *func, *args, *keyw = NULL;
struct bootstate *boot;
unsigned long ident;
//下面都是参数检测逻辑, thread.Thread()里面我们一般传递target、args、kwargs
if (!PyArg_UnpackTuple(fargs, "start_new_thread", 2, 3,
&func, &args, &keyw))
return NULL;
//target必须可调用
if (!PyCallable_Check(func)) {
PyErr_SetString(PyExc_TypeError,
"first arg must be callable");
return NULL;
}
//args是个元组
if (!PyTuple_Check(args)) {
PyErr_SetString(PyExc_TypeError,
"2nd arg must be a tuple");
return NULL;
}
//kwargs是个字典
if (keyw != NULL && !PyDict_Check(keyw)) {
PyErr_SetString(PyExc_TypeError,
"optional 3rd arg must be a dictionary");
return NULL;
}
//创建bootstate结构体实例
/*
struct bootstate {
PyInterpreterState *interp;
PyObject *func;
PyObject *args;
PyObject *keyw;
PyThreadState *tstate;
};
*/
boot = PyMem_NEW(struct bootstate, 1);
if (boot == NULL)
return PyErr_NoMemory();
//获取进程状态对象、函数、args、kwargs
boot->interp = _PyInterpreterState_Get();
boot->func = func;
boot->args = args;
boot->keyw = keyw;
boot->tstate = _PyThreadState_Prealloc(boot->interp);
if (boot->tstate == NULL) {
PyMem_DEL(boot);
return PyErr_NoMemory();
}
Py_INCREF(func);
Py_INCREF(args);
Py_XINCREF(keyw);
//初始化多线程环境,记住这一步
PyEval_InitThreads(); /* Start the interpreter's thread-awareness */
//创建线程, 返回id
ident = PyThread_start_new_thread(t_bootstrap, (void*) boot);
if (ident == PYTHREAD_INVALID_THREAD_ID) {
PyErr_SetString(ThreadError, "can't start new thread");
Py_DECREF(func);
Py_DECREF(args);
Py_XDECREF(keyw);
PyThreadState_Clear(boot->tstate);
PyMem_DEL(boot);
return NULL;
}
return PyLong_FromUnsignedLong(ident);
}因此在这个函数中,我们看到Python虚拟机通过三个主要的动作完成一个线程的创建。
1. 创建并初始化bootstate结构体实例对象boot,在boot中,会保存一些相关信息2. 初始化Python的多线程环境3. 以boot为参数,创建子线程,子线程也会对应操作系统的原生线程
另外我们看到了这一步:boot->interp = _PyInterpreterState_Get();,说明boost保存了Python的 PyInterpreterState 对象,这个对象中携带了Python的模块对象池(module pool)这样的全局信息,Python中所有的thread都会保存这些全局信息。
我们在下面还看到了多线程环境的初始化动作,这一点需要注意,Python在启动的时候是不支持多线程的。换言之,Python中支持多线程的数据结构、以及GIL都是没有被创建的。因为对多线程的支持是需要代价的,如果上来就激活了多线程,但是程序却只有一个主线程,那么Python仍然会执行所谓的线程调度机制,只不过调度完了还是它自己,所以这无异于在做无用功。因此Python将开启多线程的权利交给了程序员,自己在启动的时候是单线程的,既然是单线程,自然就不存在线程调度了、当然也没有GIL。一旦用户调用了threading.Thread(...).start() => _thread.start_new_thread(),则代表明确地指示虚拟机要创建新的线程了,这个时候Python虚拟机就知道自己该创建与多线程相关的东西了,比如:数据结构、环境、以及那个至关重要的GIL。
建立多线程环境
多线程环境的建立,说的直白一点,主要就是创建GIL。我们已经知道了GIL对于Python的多线程机制的重要意义,那么这个GIL是如何实现的呢?这是一个比较有趣的问题,下面我们就来看看GIL长什么样子吧。
//include/internal/pycore_pystate.h
struct _ceval_runtime_state {
/* 递归限制, 可以通过sys.getrecursionlimit()查看 */
int recursion_limit;
/*
记录是否对任意线程启用跟踪,同时计算 tstate->c_tracefunc 为空的线程数。
如果该值为0,那么将不会检查该线程的 c_tracefunc
这会加快 PyEval_EvalFrameEx() 中 fast_next_opcode 后的if语句
这里我们不做深入讨论
*/
int tracing_possible;
//eval循环中所有跳出快速通道的请求, 不深入讨论
_Py_atomic_int eval_breaker;
//放弃GIL的请求
_Py_atomic_int gil_drop_request;
//线程调度相关, 比如: 加锁
struct _pending_calls pending;
//信号检测相关
_Py_atomic_int signals_pending;
//重点来了, GIL, 我们看到GIL是一个struct _gil_runtime_state
struct _gil_runtime_state gil;
};所以GIL在Python的底层是一个结构体,这个结构体藏身于 include/internal/pycore_gil 中。
//Python/ceval_gil.h
#define DEFAULT_INTERVAL 5000
//include/internal/pycore_gil
struct _gil_runtime_state {
/* 一个线程拥有gil的间隔,默认是5000微妙,也就是我们上面用sys.getswitchinterval()得到的0.005 */
unsigned long interval;
/*最后一个持有GIL的PyThreadState(线程),
这有助于我们知道在丢弃GIL后是否还有其他线程被调度
*/
_Py_atomic_address last_holder;
/* GIL是否被获取,这个是原子性的,因为在ceval.c中不需要任何锁就能够读取它 */
_Py_atomic_int locked;
/* 从GIL创建之后,总共切换的次数 */
unsigned long switch_number;
/* cond允许一个或多个线程等待,直到GIL被释放 */
PyCOND_T cond;
/* mutex则是负责保护上面的变量 */
PyMUTEX_T mutex;
#ifdef FORCE_SWITCHING
/* "GIL等待线程"在被调度获取GIL之前, "GIL释放线程"一致处于等待状态 */
PyCOND_T switch_cond;
PyMUTEX_T switch_mutex;
#endif
};所以我们看到gil是struct _gil_runtime_state 类型,然后内嵌在结构体 struct _ceval_runtime_state 里面。
gil是一个结构体实例,根据里面的gil.locked判断这个gil有没有人获取,而这个locked可以看成是一个布尔变量,其访问受到gil.mutex保护,是否改变则取决于gil.cond。在持有gil的线程中,主循环(PyEval_EvalFrameEx)必须能通过另一个线程来按需释放gil。
并且我们知道在创建多线程的时候,首先是需要调用 PyEval_InitThreads 进行初始化的。我们就来看看这个函数,位于 Python/ceval.c 中。
void
PyEval_InitThreads(void)
{
//获取运行时状态对象
_PyRuntimeState *runtime = &_PyRuntime;
//拿到ceval, struct _ceval_runtime_state类型, gil就在里面
struct _ceval_runtime_state *ceval = &runtime->ceval;
//获取gil
struct _gil_runtime_state *gil = &ceval->gil;
//如果gil已经创建,那么直接返回
if (gil_created(gil)) {
return;
}
//线程的初始化
PyThread_init_thread();
//创建gil
create_gil(gil);
//获取线程状态对象
PyThreadState *tstate = _PyRuntimeState_GetThreadState(runtime);
//gil创建了,那么就要拿到这个gil
take_gil(ceval, tstate);
//我们说这个是和线程调度相关的
struct _pending_calls *pending = &ceval->pending;
//如果拿到gil了,其它线程就不能获取了,那么不好意思这个时候要加锁
pending->lock = PyThread_allocate_lock();
if (pending->lock == NULL) {
Py_FatalError("Can't initialize threads for pending calls");
}
}然后我们看看 gil_created 、 create_gil 、 take_gil 这三个函数,我们说它是用来检测 gil是否被创建、创建gil、和获取gil,定义在 Python/ceval_gil.h 中。
static int gil_created(struct _gil_runtime_state *gil)
{
//我们看到这个gil_created就是用来检测gil有没有被创建的
return (_Py_atomic_load_explicit(&gil->locked, _Py_memory_order_acquire) >= 0);
}
static void create_gil(struct _gil_runtime_state *gil)
{
//这里是创建gil
//我们看到这里负责初始化gil里面的成员
MUTEX_INIT(gil->mutex);
#ifdef FORCE_SWITCHING
MUTEX_INIT(gil->switch_mutex);
#endif
COND_INIT(gil->cond);
#ifdef FORCE_SWITCHING
COND_INIT(gil->switch_cond);
#endif
_Py_atomic_store_relaxed(&gil->last_holder, 0);
_Py_ANNOTATE_RWLOCK_CREATE(&gil->locked);
_Py_atomic_store_explicit(&gil->locked, 0, _Py_memory_order_release);
}
static void
take_gil(struct _ceval_runtime_state *ceval, PyThreadState *tstate)
{
if (tstate == NULL) {
Py_FatalError("take_gil: NULL tstate");
}
struct _gil_runtime_state *gil = &ceval->gil;
int err = errno;
MUTEX_LOCK(gil->mutex);
//判断gil是否被释放, 如果被释放, 那么直接跳转到_ready
if (!_Py_atomic_load_relaxed(&gil->locked)) {
goto _ready;
}
while (_Py_atomic_load_relaxed(&gil->locked)) {
int timed_out = 0;
unsigned long saved_switchnum;
//如果没有释放,代表gil被人使用了,会一直循环请求获取gil
//.....
//.....
}
_ready:
#ifdef FORCE_SWITCHING
//.....
/* 获取到gil的时候,那么会通过_Py_atomic_store_relaxed对其再次上锁 */
_Py_atomic_store_relaxed(&gil->locked, 1);
_Py_ANNOTATE_RWLOCK_ACQUIRED(&gil->locked, /*is_write=*/1);
//.....
}事实上,Python的多线程机制和平台有关系,需要进行统一的封装。比如:线程的销毁,Windows系统下就位于 Python/thread_nt.h 中,可以自己看一看。
总之Python的线程在获取gil的时候,会检查当前gil是否可用。而其中的locked域就是指示当前gil是否可用,如果这个值为0,那么代表可用,那么就必须要将gil的locked设置为1,表示当前gil已被占用。一旦当该线程释放gil的时候,就一定要将该值减去1,这样gil的值才会从1变成0,才能被其他线程使用,所以官方把gil的locked说成是布尔类型也不是没道理的。
最终在一个线程释放gil时,会通知所有在等待gil的线程,这些线程会被操作系统唤醒。但是这个时候会选择哪一个线程执行呢?之前说了,这个时候Python会直接借用操作系统的调度机制随机选择一个。
线程状态保护机制
要剖析线程状态的保护机制,我们首先需要回顾一下线程状态对象。在Python中肯定要有对象负责记录对应线程的状态信息,这个对象就是PyThreadState对象。
每一个PyThreadState对象中都保存着当前的线程的PyFrameObject、线程id这样的信息,因为这些信息是需要被线程访问的。假设线程A访问线程对象,但是线程对象里面存储的却是B的id,这样的话就完蛋了。因此Python内部必须有一套机制,这套机制与操作系统管理进程的机制非常类似。在线程切换的时候,会保存当前线程的上下文,并且还能够进行恢复。在Python内部,维护这一个全局变量,当前活动线程所对应的线程状态对象就保存在该变量里。当Python调度线程时,会将被激活的线程所对应的线程状态对象赋给这个全局变量,让其始终保存活动线程的状态对象。
但是这样就引入了一个问题:Python如何在调度线程时,获得被激活线程对应的状态对象呢?其实Python内部会通过一个单项链表来管理所有的Python线程状态对象,当需要寻找一个线程对应的状态对象时,就遍历这个链表,搜索其对应的状态对象。
而对这个状态对象链表的访问,则不必在gil的保护下进行。因为对于这个状态对象链表,python会专门创建一个独立的锁,专职对这个链表进行保护,而且这个锁的创建是在python初始化的时候完成的。
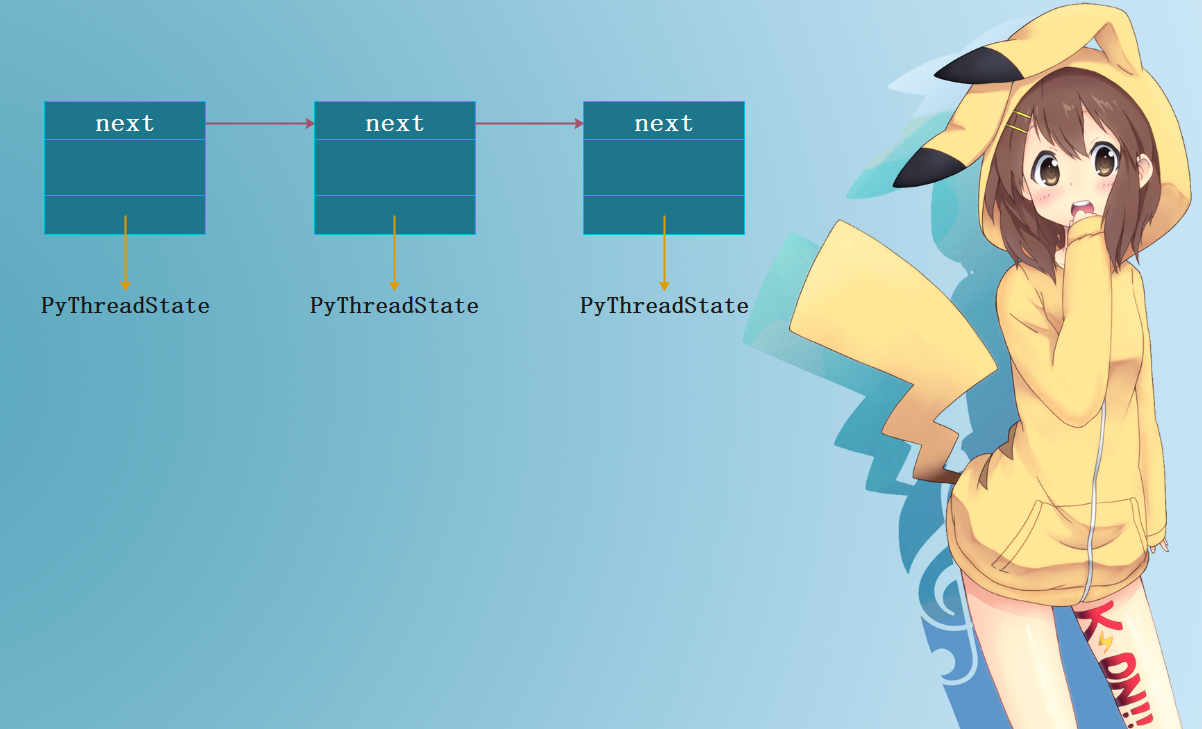
从gil到字节码解释器
我们知道创建线程对象是通过 PyThreadState_New 函数创建的:
//Python/pystate.c
PyThreadState *
PyThreadState_New(PyInterpreterState *interp)
{
return new_threadstate(interp, 1);
}
static PyThreadState *
new_threadstate(PyInterpreterState *interp, int init)
{
_PyRuntimeState *runtime = &_PyRuntime;
//创建线程对象
PyThreadState *tstate = (PyThreadState *)PyMem_RawMalloc(sizeof(PyThreadState));
if (tstate == NULL) {
return NULL;
}
//用于获取当前线程的frame
if (_PyThreadState_GetFrame == NULL) {
_PyThreadState_GetFrame = threadstate_getframe;
}
//下面是线程的相关属性
tstate->interp = interp;
tstate->frame = NULL;
tstate->recursion_depth = 0;
tstate->overflowed = 0;
tstate->recursion_critical = 0;
tstate->stackcheck_counter = 0;
tstate->tracing = 0;
tstate->use_tracing = 0;
tstate->gilstate_counter = 0;
tstate->async_exc = NULL;
tstate->thread_id = PyThread_get_thread_ident();
tstate->dict = NULL;
tstate->curexc_type = NULL;
tstate->curexc_value = NULL;
tstate->curexc_traceback = NULL;
tstate->exc_state.exc_type = NULL;
tstate->exc_state.exc_value = NULL;
tstate->exc_state.exc_traceback = NULL;
tstate->exc_state.previous_item = NULL;
tstate->exc_info = &tstate->exc_state;
tstate->c_profilefunc = NULL;
tstate->c_tracefunc = NULL;
tstate->c_profileobj = NULL;
tstate->c_traceobj = NULL;
tstate->trash_delete_nesting = 0;
tstate->trash_delete_later = NULL;
tstate->on_delete = NULL;
tstate->on_delete_data = NULL;
tstate->coroutine_origin_tracking_depth = 0;
tstate->async_gen_firstiter = NULL;
tstate->async_gen_finalizer = NULL;
tstate->context = NULL;
tstate->context_ver = 1;
tstate->id = ++interp->tstate_next_unique_id;
if (init) {
//其它的都是设置属性,我们在前面章节已经见过了
//之所以又拿出来,是因为关键的这一步
_PyThreadState_Init(runtime, tstate);
}
HEAD_LOCK(runtime);
tstate->prev = NULL;
tstate->next = interp->tstate_head;
if (tstate->next)
tstate->next->prev = tstate;
interp->tstate_head = tstate;
HEAD_UNLOCK(runtime);
return tstate;
}
//这一步_PyThreadState_Init就表示将线程对应的线程对象放入到我们刚才说的那个"线程状态对象链表"当中
void
_PyThreadState_Init(_PyRuntimeState *runtime, PyThreadState *tstate)
{
_PyGILState_NoteThreadState(&runtime->gilstate, tstate);
}这里有一个特别需要注意的地方,就是当前活动的Python线程不一定获得了gil。比如主线程获得了gil,但是子线程还没有申请gil,那么操作系统也不会将其挂起。由于主线程和子线程都对应操作系统的原生线程,所以操作系统系统是可能在主线程和子线程之间切换的,因为操作系统级别的线程调度和Python级别的线程调度是不同的。当所有的线程都完成了初始化动作之后,操作系统的线程调度和Python的线程调度才会统一。那时python的线程调度会迫使当前活动线程释放gil,而这一操作会触发操作系统内核的用于管理线程调度的对象,进而触发操作系统对线程的调度。所以我们说,Python对线程的调度是交给操作系统的(使用的是操作系统内核调度线程的调度机制),当操作系统随机选择一个线程的时候,Python就会根据这个线程去线程状态对象链表当中找到对应的线程状态对象,并赋值给那个保存当前线程活动状态对象的全局变量。从而开始获取gil,执行字节码,执行一段时间,再次被强迫释放gil,然后操作系统再次调度,选择一个线程,再获取对应的线程状态对象,然后该线程获取gil,执行一段时间字节码,再次被强迫释放gil,然后操作系统再次随机选择,依次往复。。。。。。
显然,当子线程还没有获取gil的时候,相安无事。然而一旦 PyThreadState_New 之后,多线程机制初始化完成,那么子线程就开始互相争夺话语权了。
//Modules/_threadmodule.c
static void
t_bootstrap(void *boot_raw)
{
//线程信息都在里面
struct bootstate *boot = (struct bootstate *) boot_raw;
//线程状态对象
PyThreadState *tstate;
PyObject *res;
//获取线程状态对象
tstate = boot->tstate;
//拿到线程id
tstate->thread_id = PyThread_get_thread_ident();
_PyThreadState_Init(&_PyRuntime, tstate);
//下面说
PyEval_AcquireThread(tstate);
//进程内部的线程数量+1
tstate->interp->num_threads++;
//执行字节码
res = PyObject_Call(boot->func, boot->args, boot->keyw);
if (res == NULL) {
if (PyErr_ExceptionMatches(PyExc_SystemExit))
/* SystemExit is ignored silently */
PyErr_Clear();
else {
_PyErr_WriteUnraisableMsg("in thread started by", boot->func);
}
}
else {
Py_DECREF(res);
}
Py_DECREF(boot->func);
Py_DECREF(boot->args);
Py_XDECREF(boot->keyw);
PyMem_DEL(boot_raw);
tstate->interp->num_threads--;
PyThreadState_Clear(tstate);
PyThreadState_DeleteCurrent();
PyThread_exit_thread();
}这里面有一个 PyEval_AcquireThread ,之前我们没有说,但如果我要说它是做什么的你就知道了。在 PyEval_AcquireThread 中,子线程进行了最后的冲刺,于是在里面它通过 PyThread_acquire_lock 争取gil。到了这一步,子线程将自己挂起了,操作系统没办法靠自己的力量将其唤醒,只能等待Python的线程调度机制强迫主线程放弃gil后,触发操作系统内核的线程调度,子线程才会被唤醒。然而当子线程被唤醒之后,主线程却又陷入了苦苦的等待当中,同样苦苦地等待这Python强迫子线程放弃gil的那一刻。(假设我们这里只有一个主线程和一个子线程)
当子线程被Python的线程调度机制唤醒之后,它所做的第一件事就是通过 PyThreadState_Swap 将Python维护的当前线程状态对象设置为其自身的状态对象,就如同操作系统进程的上下文环境恢复一样。这个 PyThreadState_Swap 我们也没有详细展开说,因为有些东西我们只需要知道是干什么的就行。
子线程获取了gil之后,还不算成功,因为它还没有进入字节码解释器(想象成大大的for循环,里面有一个巨大的switch)。当Python线程唤醒子线程之后,子线程将回到t_bootstrap,并进入 PyObject_Call ,从这里一路往前,最终调用 PyEval_EvalFrameEx ,才算是成功。因为 PyEval_EvalFrameEx 执行的是字节码指令,而Python最终执行的也是一个字节码,所以此时才算是真正的执行,之前的都只能说是初始化。当进入 PyEval_EvalFrameEx 的那一刻,子线程就和主线程一样,完全受Python线程度调度机制控制了。
Python的线程调度
标准调度
当主线程和子线程都进入了Python解释器后,Python的线程之间的切换就完全由Python的线程调度机制掌控了。Python的线程调度机制肯定是在Python解释器核心 PyEval_EvalFrameEx 里面的,因为线程是在执行字节码的时候切换的,那么肯定是在 PyEval_EvalFrameEx 里面。而在分析字节码的时候,我们看到过 PyEval_EvalFrameEx ,尽管说它是字节码执行的核心,但是它实际上调用了其它的函数,但毕竟是从它开始的,所以我们还是说字节码核心是 PyEval_EvalFrameEx 。总之,在分析字节码的时候,我们并没有看线程的调度机制,那么下面我们就来分析一下。
//ceval.c
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
for (;;) {
/* Give another thread a chance */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) {
Py_FatalError("ceval: tstate mix-up");
}
//释放gil,给其他线程一个机会
drop_gil(ceval, tstate);
/* Other threads may run now */
//你一旦释放了,那么就必须要再次申请,才能等待下一次被调度。
take_gil(tstate);
}
}主线程获得了gil执行字节码,但是我们知道在Python2中是通过执行字节码数量(_Py_Ticker)判断的,每执行一条字节码这个_Py_Ticker将减少1,初始为100。而在Python3中,则是通过执行时间来判断的,默认是0.005秒。一旦达到了执行时间,那么主线程就会将维护当前线程状态对象的全局变量设置为NULL并释放掉gil,这时候由于等待gil而被挂起的子线程被操作系统的线程调度机制重新唤醒,从而进入 PyEval_EvalFrameEx 。而对于主线程,虽然它失去了gil,但是由于它没有被挂起,所以对于操作系统的线程调度机制,它是可以再次被切换为活动线程的。
当操作系统的调度机制将主线程切换为活动线程的时候,主线程将主动申请gil,但由于gil被子线程占有,主线程将自身挂起。从这时开始,操作系统就不能再将主线程切换为活动线程了。所以我们发现,线程释放gil并不是马上就被挂起的,而是在释放完之后重新申请gil的时候才被挂起的。然后子线程执行0.005s之后,又会释放gil,申请gil,将自身挂起。而释放gil,会触发操作系统线程调度机制,唤醒主线程,如果是多个子线程的话,那么会从挂起的主线程和其它子线程中随机选择一个恢复。当主线程执行一段时间之后,又给子线程,如此反复,从而实现对Python多线程的支持。
阻塞调度
标准调度就是Python的调度机制掌控的,每个线程都是相当公平的。但是如果仅仅只有标准调度的话,那么可以说Python的多线程没有任何意义,但为什么可以很多场合使用多线程呢?就是因为调度除了标准调度之外,还存在阻塞调度。
阻塞调度是指,当某个线程遇到io阻塞的时候,会主动释放gil,让其它线程执行,因为io是不耗费cpu的。假设time.sleep,或者从网络上请求数据等等,这些都是处于io阻塞,那么会发生线程调度,当阻塞的线程可以执行了(如:sleep结束,请求的数据成功返回),那么再切换回来。除了这一种情况之外,还有一种情况,也会导致线程不得不挂起,那就是input函数等待用户输入,这个时候也不得不释放gil。
Python子线程的销毁
我们创建一个子线程的时候,往往是执行一个函数,或者重写一个类继承自threading.Thread,当然Python的threading模块我们后面会介绍。当一个子线程执行结束之后,Python肯定是要把对应的子线程销毁的,当然销毁主线程和销毁子线程是不同的,销毁主线程必须要销毁Python的运行时环境,而子线程的销毁则不需要这些动作,因此我们只看子线程的销毁。
通过前面的分析我们知道,线程的主体框架是在t_bootstrap中:
//Modules/_threadmodule.c
static void
t_bootstrap(void *boot_raw)
{
struct bootstate *boot = (struct bootstate *) boot_raw;
PyThreadState *tstate;
PyObject *res;
//......
Py_DECREF(boot->func);
Py_DECREF(boot->args);
Py_XDECREF(boot->keyw);
PyMem_DEL(boot_raw);
tstate->interp->num_threads--;
PyThreadState_Clear(tstate);
PyThreadState_DeleteCurrent();
PyThread_exit_thread();
}Python首先会将进程内部的线程数量自减1,然后通过 PyThreadState_Clear 清理当前线程所对应的线程状态对象。所谓清理实际上比较简单,就是改变引用计数。随后,Python通过 PyThreadState_DeleteCurrent 函数释放gil。
//Modules/pystate.c
void
PyThreadState_DeleteCurrent()
{
_PyThreadState_DeleteCurrent(&_PyRuntime);
}
static void
_PyThreadState_DeleteCurrent(_PyRuntimeState *runtime)
{
struct _gilstate_runtime_state *gilstate = &runtime->gilstate;
PyThreadState *tstate = _PyRuntimeGILState_GetThreadState(gilstate);
if (tstate == NULL)
Py_FatalError(
"PyThreadState_DeleteCurrent: no current tstate");
tstate_delete_common(runtime, tstate);
if (gilstate->autoInterpreterState &&
PyThread_tss_get(&gilstate->autoTSSkey) == tstate)
{
PyThread_tss_set(&gilstate->autoTSSkey, NULL);
}
_PyRuntimeGILState_SetThreadState(gilstate, NULL);
PyEval_ReleaseLock();
}然后首先会删除当前的线程状态对象,然后通过 PyEval_ReleaseLock 释放gil。当然这只是完成了绝大部分的销毁工作,至于剩下的收尾工作就依赖于对应的操作系统了,当然这跟我们也就没关系了。
Python线程的用户级互斥与同步
我们知道,Python的线程在gil的控制之下,线程之间对Python提供的c api访问都是互斥的,并且每次在字节码执行的过程中不会被打断,这可以看做是Python的内核级的用户互斥。但是这种互斥不是我们能够控制的,内核级通过gil的互斥保护了内核共享资源,比如del obj,它对应的指令是DELETE_NAME,这个是不会被打断的。但是像n += 1这种一行代码对应多条字节码,即便是有gil,但由于在执行到一半的时候,碰巧gil释放了,那么也会出岔子。所以我们还需要一种互斥,也就是用户级互斥。
实现用户级互斥的一种方法就是加锁,我们来看看Python提供的锁。
static PyMethodDef lock_methods[] = {
{"acquire_lock", (PyCFunction)(void(*)(void))lock_PyThread_acquire_lock,
METH_VARARGS | METH_KEYWORDS, acquire_doc},
{"acquire", (PyCFunction)(void(*)(void))lock_PyThread_acquire_lock,
METH_VARARGS | METH_KEYWORDS, acquire_doc},
{"release_lock", (PyCFunction)lock_PyThread_release_lock,
METH_NOARGS, release_doc},
{"release", (PyCFunction)lock_PyThread_release_lock,
METH_NOARGS, release_doc},
{"locked_lock", (PyCFunction)lock_locked_lock,
METH_NOARGS, locked_doc},
{"locked", (PyCFunction)lock_locked_lock,
METH_NOARGS, locked_doc},
{"__enter__", (PyCFunction)(void(*)(void))lock_PyThread_acquire_lock,
METH_VARARGS | METH_KEYWORDS, acquire_doc},
{"__exit__", (PyCFunction)lock_PyThread_release_lock,
METH_VARARGS, release_doc},
{NULL, NULL} /* sentinel */
};这些方法我们肯定都见过,acquire表示上锁、release就是释放。假设有两个线程A和B,A线程执行了lock.acquire(),然后执行下面的代码。这个时候依旧会进行线程调度,线程B执行的时候,也遇到了lock.acquire(),那么不好意思B线程就只能在这里等着了。没错,是轮到B线程执行了,但是由于我们在用户级层面上设置了一把锁lock,而这把锁已经被A线程获取了,那么即使后面切换到B线程,但是在A还没有lock.release()的时候,B也只能卡在lock.acquire()上面。因为A先拿到了锁,那么只要A不释放,B就拿不到锁,从而一直卡在lock.acquire()上面。
用户级互斥:即便你拿到了GIL,你也无法执行。
Python的threading模块
上面说了这么多,那么我们来看看Python中的threading模块,下面就是从Python层面上介绍这个模块的使用方法、api。
创建一个线程
import threading
def hello():
print("hello world")
# 创建一个线程
t = threading.Thread(target=hello, name="线程1")
"""
target:执行的函数
args:位置参数
kwargs:关键字参数
name:线程名字
daemon:布尔类型。表示是否设置为守护线程。设置为守护线程,那么当主线程执行结束会立即自杀
默认不是守护线程,表示主线程执行完毕但不会退出,而是等待子线程执行结束才会退出。
"""
# 我们调用threading.Thread会创建一个线程
# 介绍几个简单的属性吧
# 1.拿到线程名字,等价于t.getName()
print(t.name)
# 2.查看是否是守护线程,等价于t.isDaemon()
print(t.daemon) # False
# 3.线程创建之后,还可以重新设置名字、或者守护线程
t.setName("线程2")
t.setDaemon(True)
print(t.getName()) # 线程2
print(t.isDaemon()) # True启动线程
import threading
l = []
def hello():
import time
time.sleep(1)
l.append(123)
print("hello world")
# 创建一个线程
t = threading.Thread(target=hello, name="线程1")
# 线程创建好了,但是我们如何启动呢?
# 直接调用t.start()即可。
t.start()
print(l)
"""
[]
hello world
"""我们看到启动一个子线程之后,主线程是不会等待子线程的,而是会继续往下走。因此在子线程进行append之前,主线程就已经打印了。那么如何等待子线程执行完毕之后,再让主线程往下走呢?
import threading
l = []
def hello():
import time
time.sleep(1)
l.append(123)
print("hello world")
# 创建一个线程
t = threading.Thread(target=hello, name="线程1")
t.start()
# 这里就表示必须等t这个线程执行完毕,主线程才能向下走。
# 当然这里面是可以传递一个超时时间的,如果执行完毕那么主线程往下走
# 但是执行完毕之前,时间到了,主线程也会向下走
t.join()
print(l)
"""
hello world
[123]
"""
# 由于多个线程操作系统调度,所以无法决定谁先打印。
# 但是我们看到确实是等待子线程结束之后才向下走的
# 如果我们没有写t.jojn()
# 那么主线程执行完毕之后,会在最后默认执行一个join,不然它就直接结束了。
# 如果是守护线程的话,那么就不用等了,直接结束
# 如果是多个子线程,同样的逻辑突然发现这个模块的api实在简单,没啥可介绍的。可以直接网上搜索。
小结
这次我们算是将Python的多线程分析完毕了,很多人都说Python的多线程比较”鸡肋”,主要就是因为GIL导致Python无法利用多核。但是GIL也是有它的优点的,所以关于GIL也是仁者见仁智者见智吧。