Python 现在如此流行,拥有众多开源、高质量的第三方库是一个重要原因,不过 Python 的简单、灵巧、容易上手也是功不可没的,而其背后的内置函数(类)则起到了很大的作用。举个栗子:
Tags:
via Pocket https://ift.tt/37kR0yT original site
February 16, 2021 at 10:16PM
Comments
from: github-actions[bot] on: 2/18/2021
《深度剖析CPython解释器》29. 源码解密 map、filter、zip 底层实现,对比列表解析式 - 古明地盆 - 博客园
《深度剖析CPython解释器》29. 源码解密 map、filter、zip 底层实现,对比列表解析式
楔子
Python 现在如此流行,拥有众多开源、高质量的第三方库是一个重要原因,不过 Python 的简单、灵巧、容易上手也是功不可没的,而其背后的内置函数(类)则起到了很大的作用。举个栗子:
numbers = [1, 2, 3, 4, 5]
# 将里面每一个元素都加1
print(list(map(lambda x: x + 1, numbers))) # [2, 3, 4, 5, 6]
strings = ["abc", "d", "def", "kf", "ghtc"]
# 筛选出长度大于等于3的
print(list(filter(lambda x: len(x) >= 3, strings))) # ['abc', 'def', 'ghtc']
keys = ["name", "age", "gender"]
values = ["夏色祭", 17, "female"]
# 将keys 和 values 里面的元素按照顺序组成字典
print(dict(zip(keys, values))) # {'name': '夏色祭', 'age': 17, 'gender': 'female'}我们看到一行代码就搞定了,那么问题来了,这些内置函数(类)在底层是怎么实现的呢?下面我们就来通过源码来分析一下,这里我们介绍 map、filter、zip。
首先这些类(map、filter、zip都是类)都位于 builtin 名字空间中,而我们之前在介绍源码的时候提到过一个文件:Python/bltinmodule.c,我们说该文件是和内置函数(类)相关的,那么显然 map、filter、zip 也藏身于此。
Python已经进化到 3.9.0 了,所以这里就使用 Python3.9.0 的源码进行分析吧。
map底层实现
我们知道map是将一个序列中的每个元素都作用于同一个函数(当然类、方法也可以):
当然,我们知道调用map的时候并没有马上执行上面的操作,而是返回一个map对象。既然是对象,那么底层必有相关的定义。
typedef struct {
PyObject_HEAD
PyObject *iters;
PyObject *func;
} mapobject;PyObject_HEAD:见过很多次了,它是Python中任何对象都会有的头部信息。包含一个引用计数ob_refcnt、和一个类型对象的指针ob_type;
iters:一个指针,这里实际上是一个PyTupleObject *,以
map(lambda x: x + 1, [1, 2, 3])为例,那么这里的 iters 就相当于是([1, 2, 3, 4, 5].__iter__(),)。至于为什么,分析源码的时候就知道了;func:显然就是函数指针了,PyFunctionObject *;
通过底层结构体定义,我们也可以得知在调用map时并没有真正的执行;对于函数和可迭代对象,只是维护了两个指针去指向它。
而一个PyObject占用16字节,再加上两个8字节的指针总共32字节。因此在64位机器上,任何一个map对象所占大小都是32字节。
numbers = list(range(100000))
strings = ["abc", "def"]
# 都占32字节
print(map(lambda x: x * 3, numbers).__sizeof__()) # 32
print(map(lambda x: x * 3, strings).__sizeof__()) # 32再来看看map的用法,Python中的 map 不仅可以作用于一个序列,还可以作用于任意多个序列。
m1 = map(lambda x: x[0] + x[1] + x[2], [(1, 2, 3), (2, 3, 4), (3, 4, 5)])
print(list(m1)) # [6, 9, 12]
# map 还可以接收任意个可迭代对象
m2 = map(lambda x, y, z: x + y + z, [1, 2, 3], [2, 3, 4], [3, 4, 5])
print(list(m2)) # [6, 9, 12]
# 所以底层结构体中的iters在这里就相当于 ([1, 2, 3].__iter__(), [2, 3, 4].__iter__(), [3, 4, 5].__iter__())
# 我们说map的第一个参数是一个函数, 后面可以接收任意多个可迭代对象
# 但是注意: 可迭代对象的数量 和 函数的参数个数 一定要匹配
m3 = map(lambda x, y, z: str(x) + y + z, [1, 2, 3], ["a", "b", "c"], "abc")
print(list(m3)) # ['1aa', '2bb', '3cc']
# 但是可迭代对象之间的元素个数不要求相等, 会以最短的为准
m4 = map(lambda x, y, z: x + y + z, [1, 2, 3], [2, 3], [3, 4, 5])
print(list(m4)) # [6, 9]
# 当然也支持更加复杂的形式
m5 = map(lambda x, y: x[0] + x[1] + y, [(1, 2), (2, 3)], [3, 4])
print(list(m5)) # [6, 9]所以我们看到 map 会将后面所有可迭代对象中的每一个元素按照顺序依次取出,然后传递到函数中,因此函数的参数个数 和 可迭代对象的个数 一定要相等。
那么map对象在底层是如何创建的呢?很简单,因为map是一个类,那么调用的时候一定会执行里面的 __new__ 方法。
static PyObject *
map_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *it, *iters, *func;
mapobject *lz;
Py_ssize_t numargs, i;
// map对象在底层对应的是 mapobject、map类本身在底层对应的则是 PyMap_Type
// _PyArg_NoKeywords表示检验是否没有传递关键字参数, 如果没传递, 那么结果为真; 传递了, 结果为假;
if (type == &PyMap_Type && !_PyArg_NoKeywords("map", kwds))
// 可以看到 map 不接受关键字参数
// 如果传递了, 那么会报如下错误: TypeError: map() takes no keyword arguments, 可以自己尝试一下
return NULL;
// 位置参数都在 args 里面, 上面的 kwds 是关键字参数
// 这里获取位置参数的个数, 1个函数、numargs - 1个可迭代对象, 这里的args 是一个 PyTupleObject *
numargs = PyTuple_Size(args);
// 如果参数个数小于2
if (numargs < 2) {
// 抛出 TypeError, 表示 map 至少接受两个位置参数: 一个函数 和 至少一个可迭代对象
PyErr_SetString(PyExc_TypeError,
"map() must have at least two arguments.");
return NULL;
}
// 申请一个元组, 容量为 numargs - 1, 用于存放传递的所有可迭代对象(对应的迭代器)
iters = PyTuple_New(numargs-1);
// 为NULL表示申请失败
if (iters == NULL)
return NULL;
// 依次循环
for (i=1 ; i<numargs ; i++) {
// PyTuple_GET_ITEM(args, i) 表示获取索引为 i 的可迭代对象
// PyObject_GetIter 表示获取对应的迭代器, 相当于内置函数 iter
it = PyObject_GetIter(PyTuple_GET_ITEM(args, i));
// 为NULL表示获取失败, 但是iters这个元组已经申请了, 所以减少其引用计数, 将其销毁
if (it == NULL) {
Py_DECREF(iters);
return NULL;
}
// 将对应的迭代器设置在元组iters中
PyTuple_SET_ITEM(iters, i-1, it);
}
// 调用 PyMap_Type 的 tp_alloc, 为其实例对象申请空间
lz = (mapobject *)type->tp_alloc(type, 0);
// 为NULL表示申请失败, 减少iters的引用计数
if (lz == NULL) {
Py_DECREF(iters);
return NULL;
}
// 让lz的iters成员 等于 iters
lz->iters = iters;
// 获取第一个参数, 也就是函数
func = PyTuple_GET_ITEM(args, 0);
// 增加引用计数, 因为该函数被作为参数传递给map了
Py_INCREF(func);
// 让lz的func成员 等于 func
lz->func = func;
// 转成 PyObject *泛型指针, 然后返回
return (PyObject *)lz;
}所以我们看到map_new做的工作很简单,就是实例化一个map对象,然后对内部的成员进行赋值。我们用Python来模拟一下上述过程:
class MyMap:
def __new__(cls, *args, **kwargs):
if kwargs:
raise TypeError("MyMap不接受关键字参数")
numargs = len(args)
if numargs < 2:
raise TypeError("MyMap至少接收两个参数")
# 元组内部的元素不可以改变(除非本地修改), 所以这里使用列表来模拟
iters = [None] * (numargs - 1) # 创建一个长度为 numargs - 1 的列表, 元素都是None, 模拟C中的NULL
i = 1
while i < numargs: # 逐步循环
it = iter(args[i]) # 获取可迭代对象, 得到其迭代器
iters[i - 1] = it # 设置在 iters 中
i += 1
# 为实例对象申请空间
instance = object.__new__(cls)
# 设置成员
instance.iters = iters
instance.func = args[0]
return instance # 返回实例对象
m = MyMap(lambda x, y: x + y, [1, 2, 3], [11, 22, 33])
print(m) # <__main__.MyMap object at 0x00000167F4552E80>
print(m.func) # <function <lambda> at 0x0000023ABC4C51F0>
print(m.func(2, 3)) # 5
print(m.iters) # [<list_iterator object at 0x0000025F13AF2940>, <list_iterator object at 0x0000025F13AF2CD0>]
print([list(it) for it in m.iters]) # [[1, 2, 3], [11, 22, 33]]我们看到非常简单,这里我们没有设置构造函数__init__,这是因为 map 内部没有 __init__,它的成员都是在__new__里面设置的。
# map的__init__ 实际上就是 object的__init__
print(map.__init__ is object.__init__) # True
print(map.__init__) # <slot wrapper '__init__' of 'object' objects>事实上,你会发现map对象非常类似迭代器,而事实上它们也正是迭代器。
from typing import Iterable, Iterator
m = map(str, [1, 2, 3])
print(isinstance(m, Iterable)) # True
print(isinstance(m, Iterator)) # True为了能更方便地理解后续内容,这里我们来提一下Python中的迭代器,可能有人觉得Python的迭代器很神奇,但如果你看了底层实现的话,你肯定会觉得:”就这?”
// Objects/iterobject.c
typedef struct {
PyObject_HEAD
Py_ssize_t it_index; // 每迭代一次, index自增1
PyObject *it_seq; // 走到头之后, 将it_seq设置为NULL
} seqiterobject;这就是Python的迭代器,非常简单,我们直接用Python来模拟一下:
class MyIterator:
def __new__(cls, it_seq):
instance = object.__new__(cls) # 创建实例对象
instance.it_index = 0
instance.it_seq = it_seq
return instance
def __iter__(self):
return self
def __next__(self):
# 如果 self.it_seq 为None, 证明此迭代器已经迭代完毕
if self.it_seq is None:
raise StopIteration
try:
# 逐步迭代, 说白了就是使用索引获取, 每迭代一次、索引自增1
val = self.it_seq[self.it_index]
self.it_index += 1
return val
except IndexError:
# 出现索引越界, 证明已经遍历完毕
# 直接将 self.it_seq 设置为None即可
raise StopIteration
for _ in MyIterator([1, 2, 3]):
print(_, end=" ") # 1 2 3
print()
my_it = MyIterator([2, 3, 4])
# 只能迭代一次
print(list(my_it)) # [2, 3, 4]
print(list(my_it)) # []Python的迭代器底层就是这么做的,可能有人觉得这不就是把 可迭代对象 和 索引 进行了一层封装嘛。每迭代一次,索引自增1,当出现索引越界时,证明迭代完了,直接将 it_seq 设置为 NULL 即可(这也侧面说明了为什么迭代器从开始到结束只能迭代一次)。
是的,迭代器就是这么简单,没有一点神秘。当然不仅是迭代器,再比如关键字 in,在C的层面其实就是一层 for 循环罢了。下面看看源码是如何体现的:
// Objects/iterobject.c
// 创建
PyObject *
PySeqIter_New(PyObject *seq)
{
// 迭代器
seqiterobject *it;
// 如果不是一个序列的话, 那么调用失败
if (!PySequence_Check(seq)) {
PyErr_BadInternalCall();
return NULL;
}
// 申请空间
it = PyObject_GC_New(seqiterobject, &PySeqIter_Type);
// 为NULL表示申请失败
if (it == NULL)
return NULL;
// it_index 初始化为0
it->it_index = 0;
// 因为seq被传递了, 所以指向的对象的引用计数要加1
Py_INCREF(seq);
// 将成员it_seq初始化为seq
it->it_seq = seq;
// 将该迭代器对象链接到 第0代链表 中, 并由GC负责跟踪(此处和垃圾回收机制相关, 这里不做过多介绍)
_PyObject_GC_TRACK(it);
// 返回迭代器对象
return (PyObject *)it;
}
// 迭代
static PyObject *
iter_iternext(PyObject *iterator)
{
seqiterobject *it; // 迭代器对象
PyObject *seq; // 迭代器对象内部的可迭代对象
PyObject *result; // 迭代结果
assert(PySeqIter_Check(iterator)); // 一定是迭代器
it = (seqiterobject *)iterator; // 将泛型指针PyObject * 转成 seqiterobject *
seq = it->it_seq; // 获取内部可迭代对象
// 如果是NULL, 那么证明此迭代器已经迭代完毕, 直接返回NULL
if (seq == NULL)
return NULL;
// 索引达到了最大值, 因为容器内部的元素个数是有限制的; 但如果不是吃撑了写恶意代码, 这个限制几乎不可能会触发
if (it->it_index == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"iter index too large");
return NULL;
}
// 根据索引获取 seq 内部的元素
result = PySequence_GetItem(seq, it->it_index);
// 如果不为NULL, 证明确实迭代出了元素
if (result != NULL) {
// 索引自增1
it->it_index++;
// 然后返回结果
return result;
}
// 当result为NULL的时候, 证明出异常了, 也说明遍历到头了
// 进行异常匹配, 如果出现的异常能匹配 IndexError 或者 StopIteration
if (PyErr_ExceptionMatches(PyExc_IndexError) ||
PyErr_ExceptionMatches(PyExc_StopIteration))
{
// 那么不会让异常抛出, 而是通过 PyErr_Clear() 将异常回溯栈清空
// 所以使用 for i in 迭代器, 或者 list(迭代器) 等等不会报错, 原因就在于此; 尽管它们也是不断迭代, 但是在最后会捕获异常
PyErr_Clear();
// 将it_seq设置为NULL, 表示此迭代器大限已至、油尽灯枯
it->it_seq = NULL;
// 因为将it_seq赋值NULL, 那么原来的可迭代对象就少了一个引用, 因此要将引用计数减1
Py_DECREF(seq);
}
return NULL;
}所以这就是迭代器,真的一点都不神秘。
在迭代器上面多扯皮了一会儿,但这肯定是值得的,那么回到主题。我们说调用map只是得到一个map对象,从上面的分析我们也可以得出,在整个过程并没有进行任何的计算。如果要计算的话,我们可以调用__next__、或者使用for循环等等。
m = map(lambda x: x + 1, [1, 2, 3, 4, 5])
print([i for i in m]) # [2, 3, 4, 5, 6]
# 当然我们知道 for 循环的背后本质上会调用迭代器的 __next__
m = map(lambda x: int(x) + 1, "12345")
while True:
try:
print(m.__next__())
except StopIteration:
break
"""
2
3
4
5
6
"""
# 当然上面都不是最好的方式
# 如果只是单纯的将元素迭代出来, 而不做任何处理的话, 那么交给tuple、list、set等类型对象才是最佳的方式
# 像tuple(m)、list(m)、set(m)等等
# 所以如果你是[x for x in it]这种做法的话, 那么更建议你使用list(m), 效率会更高, 因为它用的是C中的for循环
# 当然不管是哪种做法, 底层都是一个不断调用__next__、逐步迭代的过程所以下面我们来看看map底层是怎么做的?
static PyObject *
map_next(mapobject *lz)
{
// small_stack显然是一个数组, 里面存放 PyObject *, 显然它用来存放 map 中所有可迭代对象的索引为i(i=0,1,2,3...)的元素
// 但这个_PY_FASTCALL_SMALL_STACK是什么呢? 我们需要详细说一下
PyObject *small_stack[_PY_FASTCALL_SMALL_STACK];
/*
_PY_FASTCALL_SMALL_STACK 是一个宏, 定义在 Include/cpython/abstract.h 中, 结果就等于5
small_stack这个数组会首先尝试在栈区分配,如果通过位置参数来调用一个函数的话, 可以不用申请在堆区
但是数量不能过大, 官方将这个值设置成5, 如果参数个数小于等于5的话, 便可申请在栈中
然后通过传递位置参数的方式对函数进行调用, 在C中调用一个 Python函数 有很多种方式;
这里会通过 PyObject_Vectorcall 系列函数(矢量调用, 会更快) 来对函数进行调用, 是的,调用一个函数需要借助另一个函数
之所以将其设置成5, 是为了不滥用C的栈, 从而减少栈溢出的风险
*/
// 二级指针, 指向 small_stack 数组的首元素, 所以是 PyObject **
PyObject **stack;
// 函数调用的返回值
PyObject *result = NULL;
// 获取当前的线程状态对象
PyThreadState *tstate = _PyThreadState_GET();
// 获取iters内置迭代器的数量, 同时也是调用函数时的参数数量
const Py_ssize_t niters = PyTuple_GET_SIZE(lz->iters);
// 如果这个参数小于等于5, 那么在获取这些迭代器中的元素时, 可以直接使用在C栈中申请的数组进行存储
if (niters <= (Py_ssize_t)Py_ARRAY_LENGTH(small_stack)) {
stack = small_stack;
}
else {
// 如果超过了5, 那么不好意思, 只能在堆区重新申请了
stack = PyMem_Malloc(niters * sizeof(stack[0]));
// 返回NULL, 表示申请失败, 说明没有内存了
if (stack == NULL) {
// 这里传入线程状态对象, 会在内部设置异常
_PyErr_NoMemory(tstate);
return NULL;
}
}
// 走到这里说明一切顺利, 那么下面就开始迭代了
// 如果是 map(func, [1, 2, 3], ["xx", "yy", "zz"], [2, 3, 4]), 那么第一次迭代出来的元素就是 (1, "xx", 2)
Py_ssize_t nargs = 0;
for (Py_ssize_t i=0; i < niters; i++) {
// 获取索引为i对应的迭代器,
PyObject *it = PyTuple_GET_ITEM(lz->iters, i);
// Py_TYPE表示获取对象的 ob_type(类型对象), 然后调用tp_iternext成员进行迭代
// 类似于 type(it).__next__(it)
PyObject *val = Py_TYPE(it)->tp_iternext(it);
// 如果val为NULL, 直接跳转到 exit 这个label中
if (val == NULL) {
goto exit;
}
// 将 val 设置在数组索引为i的位置中, 然后进行下一轮循环, 也就是获取下一个迭代器中的元素设置在数组stack中
stack[i] = val;
// nargs++, 和参数个数、迭代器个数 保持一致
// 如果可迭代对象个数是3, 那么小于5, 所以stack会申请在栈区; 但是在栈区申请的话, 长度默认为5, 因此后两个是元素是无效的
// 所以在调用的时候需要指定有效的参数个数
nargs++;
}
// 进行调用, 得到结果, 这个函数是Python3.9新增的; 如果是Python3.8的话, 调用的是_PyObject_FastCall
result = _PyObject_VectorcallTstate(tstate, lz->func, stack, nargs, NULL);
exit:
// 调用完毕之后, 将stack中指针指向的对象的引用计数减1
for (Py_ssize_t i=0; i < nargs; i++) {
Py_DECREF(stack[i]);
}
// 不相等的话, 说明该stack是在堆区申请的, 要释放
if (stack != small_stack) {
PyMem_Free(stack);
}
// 返回result
return result;
}然后突然发现map对象还有一个鲜为人知的一个方法,也是一个没有什么卵用的方法。说来惭愧,要不是看源码,我还真没注意过。
static PyObject *
map_reduce(mapobject *lz, PyObject *Py_UNUSED(ignored))
{
// 获取迭代器的元素个数
Py_ssize_t numargs = PyTuple_GET_SIZE(lz->iters);
// 申请一个元素, 空间是numargs + 1 个
PyObject *args = PyTuple_New(numargs+1);
Py_ssize_t i;
if (args == NULL)
return NULL;
Py_INCREF(lz->func);
// 将函数设置为args的第一个元素
PyTuple_SET_ITEM(args, 0, lz->func);
// 然后再将剩下的迭代器也设置在args中
for (i = 0; i<numargs; i++){
PyObject *it = PyTuple_GET_ITEM(lz->iters, i);
Py_INCREF(it);
PyTuple_SET_ITEM(args, i+1, it);
}
// 将 Py_TYPE(lz) 和 args 打包成一个元组返回
// 所以从结果上看, 返回的内容应该是: ( <class 'map'>, (函数, 迭代器1, 迭代器2, 迭代器3, ......) )
return Py_BuildValue("ON", Py_TYPE(lz), args);
}
static PyMethodDef map_methods[] = {
// 然后这个函数叫 __reduce__
{"__reduce__", (PyCFunction)map_reduce, METH_NOARGS, reduce_doc},
{NULL, NULL} /* sentinel */
};然后我们来演示一下:
from pprint import pprint
m = map(lambda x, y, z: x + y + z, [1, 2, 3], [2, 3, 4], [3, 4, 5])
pprint(m.__reduce__())
"""
(<class 'map'>,
(<function <lambda> at 0x000001D2791451F0>,
<list_iterator object at 0x000001D279348640>,
<list_iterator object at 0x000001D279238700>,
<list_iterator object at 0x000001D27950AF40>))
"""filter底层实现
然后我们filter的实现原理,看完了map之后,再看filter就简单许多了。
lst = [1, 2, 3, 4, 5]
print(list(filter(lambda x: x % 2 !=0, lst))) # [1, 3, 5]首先filter接收两个元素,第一个参数是一个函数(类、方法),第二个参数是一个可迭代对象。然后当我们迭代的时候会将可迭代对象中每一个元素都传入到函数中,如果返回的结果为真,则保留;为假,则丢弃。
但是,其实第一个参数除了是一个可调用的对象之外,它还可以是None。
lst = ["夏色祭", "", [], 123, 0, {}, [1]]
# 会自动选择结果为真的元素
print(list(filter(None, lst))) # ['夏色祭', 123, [1]]至于为什么,一会看源码filter的实现就清楚了。
下面看看底层结构:
typedef struct {
PyObject_HEAD
PyObject *func;
PyObject *it;
} filterobject;我们看到和map对象是一致的,没有什么区别。因为map、filter都不会立刻调用,而是返回一个相应的对象。
static PyObject *
filter_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *func, *seq; // 函数、可迭代对象
PyObject *it; // 可迭代对象的迭代器
filterobject *lz; // 返回值, filter对象
// filter也不接受关键字参数
if (type == &PyFilter_Type && !_PyArg_NoKeywords("filter", kwds))
return NULL;
// 只接受两个参数
if (!PyArg_UnpackTuple(args, "filter", 2, 2, &func, &seq))
return NULL;
// 获取seq对应的迭代器
it = PyObject_GetIter(seq);
if (it == NULL)
return NULL;
// 为filter对象申请空间
lz = (filterobject *)type->tp_alloc(type, 0);
if (lz == NULL) {
Py_DECREF(it);
return NULL;
}
// 增加函数的引用计数
Py_INCREF(func);
// 初始化成员
lz->func = func;
lz->it = it;
// 返回
return (PyObject *)lz;
}和map是类似的,因为本质上它们做的事情都是差不多的,下面看看迭代过程。
static PyObject *
filter_next(filterobject *lz)
{
PyObject *item; // 迭代器中迭代出来的每一个元素
PyObject *it = lz->it; // 迭代器
long ok; // 是否为真, 1表示真、0表示假
PyObject *(*iternext)(PyObject *); // 函数指针, 接收一个PyObject *, 返回一个PyObject *
// 如果 func == None 或者 func == bool, 那么checktrue为真; 会走单独的方法, 所以给func传递一个None是完全合法的
int checktrue = lz->func == Py_None || lz->func == (PyObject *)&PyBool_Type;
// 迭代器的 __next__ 方法
iternext = *Py_TYPE(it)->tp_iternext;
// 无限循环
for (;;) {
// 迭代出迭代器的每一个元素
item = iternext(it);
if (item == NULL)
return NULL;
// 如果checkture, 或者说如果func == None || func == bool
if (checktrue) {
// PyObject_IsTrue(item)实际上就是在判断item是否为真, 像0、长度为0的序列、False、None为假
// 另外我们在if语句的时候经常会写 if item: 这种形式, 但是很少会写 if bool(item):
// 因为bool(item)底层也是调用 PyObject_IsTrue
// 而if item: 如果你查看它的字节码的话, 会发现有这么一条指令: POP_JUMP_IF_FALSE
// 它在底层也是调用了 PyObject_IsTrue, 因此完全没有必要写成 if bool(item): 这种形式
ok = PyObject_IsTrue(item);
// 而如果func为None或者bool的话, 那么直接走PyObject_IsTrue
} else {
// 否则的话, 会调用我们传递的func
// 这里的 good 就是函数调用的返回值
PyObject *good;
// 调用函数, 将返回值赋值给good
good = PyObject_CallFunctionObjArgs(lz->func, item, NULL);
// 如果 good 等于 NULL, 说明函数调用失败; 说句实话, 源码中做的很多异常捕获都是针对解释器内部的
// 尤其像底层这种和NULL进行比较的, 我们在使用Python的时候, 很少会出现
if (good == NULL) {
Py_DECREF(item);
return NULL;
}
// 判断 good 是否为真
ok = PyObject_IsTrue(good);
Py_DECREF(good); // 减少其引用计数, 因为它不被外界所使用
}
// 如果ok大于0, 说明将item传给函数调用之后返回的结果为真, 那么将item返回
if (ok > 0)
return item;
// 同时减少其引用计数
// 如果等于0, 说明为假, 那么进行下一轮循环
Py_DECREF(item);
// 小于0的话, 表示PyObject_IsTrue调用失败了, 调用失败会返回-1
// 但还是那句话, 这种情况, 在Python的使用层面上几乎不可能发生
if (ok < 0)
return NULL;
}
}所以看到这里你还觉得Python神秘吗,从源代码层面我们看的非常流畅,只要你有一定的C语言基础即可。还是那句话,尽管我们不可能写一个解释器,因为背后涉及的东西太多了,但至少我们在看的过程中,很清楚底层到底在做什么。而且这背后的实现,如果让你设计一个方案的话,那么相信你也一样可以做到。
还是拿关键字 in 举例子,像"b" in ["a", "b", "c"]我们知道结果为真。那如果让你设计关键字 in 的实现,你会怎么做呢?反正基本上都会想到,遍历 in 后面的可迭代对象呗,将里面的元素 依次和 in前面的元素进行比较,如果出现相等的,返回真;遍历完了也没发现相等的,那么返回假。如果你是这么想的,那么恭喜你,Python解释器内部也是这么做的,我们以列表为例:
// item in 列表: 本质上就是调用 list.__contains__(列表, item) 或者 列表.__contains__(item)
static int
list_contains(PyListObject *a, PyObject *el)
{
PyObject *item; // 列表中的每一个元素
Py_ssize_t i; // 循环变量
int cmp; // 比较的结果
// cmp初始为0
for (i = 0, cmp = 0 ; cmp == 0 && i < Py_SIZE(a); ++i) {
// 获取PyListObject中的每一个元素
item = PyList_GET_ITEM(a, i);
Py_INCREF(item);
// 调用PyObject_RichCompareBool进行比较, 大于、小于、不等于之类的都是使用这个函数, 具体是哪一种则通过第三个参数控制
// 而前两个元素则是比较的对象
cmp = PyObject_RichCompareBool(el, item, Py_EQ);
Py_DECREF(item);
}
// 如果出现相等的元素, 那么cmp为1, 因此cmp == 0 && i < Py_SIZE(a)会不成立, 直接结束循环
// 如果没有出现相等的元素, 那么会一直遍历整个列表, 始终没有出现相等的元素, 那么cmp还是0
// 为1代表真, 为0代表假
return cmp;
}以上便是关键字 in,是不是很简单呢?所以个人推荐没事的话可以多读一读Python解释器,如果你不使用Python / C API进行编程的话,那么不需要你有太高的C语言水平(况且现在还有Cython)。如果你想写出高质量、并且精简利落的Python代码,那么就势必要懂得背后的实现原理。比如:我们看几道思考题,自己乱编的。
1. 为什么 方法一 要比 方法二 更高效?
lst = [1, 2, 3, 4, 5]
# 方法一
def f1():
return [f"item: {item}" for item in lst]
# 方法二
def f2():
res = []
for item in lst:
res.append(f"item: {item}")
return res所以这道题考察的实际上是列表解析为什么更快?首先Python中的变量在底层本质上都是一个泛型指针PyObject *,调用res.append的时候实际上会进行一次属性查找。会调用
PyObject_GetAttr(res, "append"),去寻找该对象是否有 append 函数,如果有的话,那么进行获取然后调用;而列表解析,Python在编译的时候看到左右的两个中括号就知道这是一个列表解析式,所以它会立刻知道自己该干什么,会直接调用C一级函数 PyList_Append,因为Python对这些内置对象非常熟悉。所以列表解析少了一层属性查找的过程,因此它的效率会更高。
2. 假设有三个变量a、b、c,三个常量 “xxx”、123、3.14,我们要判断这三个变量对应的值 和 这三个常量是否相等,该怎么做呢?注意:顺序没有要求,可以是 a == “xxx”、也可以是 b == “xxx”,只要这个三个变量对应的值正好也是 “xxx”、123、3.14 就行。
显然最方便的是使用集合:
a, b, c = 3.14, "xxx", 123
print(not {a, b, c} - {"xxx", 3.14, 123}) # True3. 令人困惑的生成器解析式,请问下面哪段代码会报错?
# 代码一
x = ("xxx" for _ in dasdasdad)
# 代码二
x = (dasdasdad for _ in "xxx")首先生成器解析式,只有在执行的时候才会真正的产出值。但是关键字 in 后面的变量是会提前确定的,所以代码一会报错,抛出 NameError;但代码二不会,因为只有在产出值的时候才会去寻找变量 dasdasdad 指向的值。
再留个两个思考题,为什么会出现这种结果呢?
# 思考题一:
class A:
x = 123
print(x)
lst = [x for _ in range(3)]
"""
123
NameError: name 'x' is not defined
"""
########################################################################
# 思考题二:
def f():
a = 123
print(eval("a"))
print([eval("a") for _ in range(3)])
f()
"""
123
NameError: name 'a' is not defined
"""像这样类似的问题还有很多很多,当然最关键的还是理解底层的数据结构 以及 解释器背后的执行原理,只有这样才能写出更加高效的代码。
回到正题,filter 也有 __reduce__ 方法,和 map 类似。
f = filter(None, [1, 2, 3, 0, "", [], "xx"])
print(f.__reduce__()) # (<class 'filter'>, (None, <list_iterator object at 0x00000239AF2AB0D0>))
print(list(f.__reduce__()[1][1])) # [1, 2, 3, 0, '', [], 'xx']zip底层实现
最后看看 zip,其实 zip 和 map 也是有着高度相似之处的,首先它们都可以接受任意个可迭代对象。而且 zip,我们完全可以使用 map 来进行模拟。
print(
list(zip([1, 2, 3], [11, 22, 33], [111, 222, 333]))
) # [(1, 11, 111), (2, 22, 222), (3, 33, 333)]
print(
list(map(lambda x, y, z: (x, y, z), [1, 2, 3], [11, 22, 33], [111, 222, 333]))
) # [(1, 11, 111), (2, 22, 222), (3, 33, 333)]
print(
list(map(lambda *args: args, [1, 2, 3], [11, 22, 33], [111, 222, 333]))
) # [(1, 11, 111), (2, 22, 222), (3, 33, 333)]
# 所以我们看到实现zip, 完全可以使用 map, 只需要多指定一个函数即可所以 zip 的底层实现同样很简单,我们来看一下:
typedef struct {
PyObject_HEAD
Py_ssize_t tuplesize;
PyObject *ittuple;
PyObject *result;
} zipobject;
// 以上便是zip对象的底层定义, 这些字段的含义, 我们暂时先不讨论, 它们会体现在zip_new方法中, 我们到时候再说目前我们根据结构体里面的成员,可以得到一个 zipobject 显然是占 40 字节的,16 + 8 + 8 + 8,那么结果是不是这样呢?我们来试一下就知道了。
z1 = zip([1, 2, 3], [11, 22, 33])
z2 = zip([1, 2, 3, 4], [11, 22, 33, 44])
z3 = zip([1, 2, 3], [11, 22, 33], [111, 222, 333])
print(z1.__sizeof__()) # 40
print(z2.__sizeof__()) # 40
print(z3.__sizeof__()) # 40所以我们分析的没有错,任何一个 zip 对象所占的大小都是 40 字节。所以在计算内存大小的时候,有人会好奇这到底是怎么计算的,其实就是根据底层的结构体进行计算的。
注意:如果你使用 sys.getsizeof 函数计算的话,可能会多出 16 个字节,这是因为对于可变对象,它们是会被 GC 跟踪的。在创建的时候,它们会被挂到零代链表中,所以它们额外还会有一个 前继指针 和 一个 后继指针,而 sys.getsizeof 将这两个指针的大小也算在内了。
下面看看 zip 对象是如何被实例化的。
static PyObject *
zip_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
zipobject *lz; // zip 对象
Py_ssize_t i; // 循环变量
PyObject *ittuple; // 所有可迭代对象的迭代器组成的元组
PyObject *result; // "代码中有体现"
Py_ssize_t tuplesize; // 可迭代对象的数量
// zip同样不需要关键字参数, 但是在3.10的时候将会提供一个关键字参数strict, 如果为True, 表示可迭代对象之间的长度必须相等, 否则报错
// strict如果为False, 则和目前是等价的, 会自动以短的为准
if (type == &PyZip_Type && !_PyArg_NoKeywords("zip", kwds))
return NULL;
// args必须使用一个PyTupleObject *
assert(PyTuple_Check(args));
// 获取可迭代对象的数量
tuplesize = PyTuple_GET_SIZE(args);
// 申请一个元组, 长度为tuplesize, 用于存放可迭代对象对应的迭代器
ittuple = PyTuple_New(tuplesize);
if (ittuple == NULL) // 为NULL表示申请失败
return NULL;
// 然后依次遍历
for (i=0; i < tuplesize; ++i) {
// 获取传递的可迭代对象
PyObject *item = PyTuple_GET_ITEM(args, i);
// 通过PyObject_GetIter获取对应的迭代器
PyObject *it = PyObject_GetIter(item);
if (it == NULL) {
// 为NULL表示获取失败, 减少ittuple的引用计数, 返回NULL
Py_DECREF(ittuple);
return NULL;
}
// 设置在ittuple中
PyTuple_SET_ITEM(ittuple, i, it);
}
// 这里又申请一个元组result, 长度也为tuplesize
result = PyTuple_New(tuplesize);
if (result == NULL) {
Py_DECREF(ittuple);
return NULL;
}
// 然后将内部的所有元素都设置为None, Py_None就是Python中的None
for (i=0 ; i < tuplesize ; i++) {
Py_INCREF(Py_None);
PyTuple_SET_ITEM(result, i, Py_None);
}
// 申请一个zip对象
lz = (zipobject *)type->tp_alloc(type, 0);
// 申请失败减少引用计数, 返回NULL
if (lz == NULL) {
Py_DECREF(ittuple);
Py_DECREF(result);
return NULL;
}
// 初始化成员
lz->ittuple = ittuple;
lz->tuplesize = tuplesize;
lz->result = result;
// 转成泛型指针PyObject *之后返回
return (PyObject *)lz;
}再来看看,zip对象的定义:
typedef struct {
PyObject_HEAD
Py_ssize_t tuplesize;
PyObject *ittuple;
PyObject *result;
} zipobject;如果以:zip([1, 2, 3], [11, 22, 33], [111, 222, 333])为例的话,那么:
tuplesize: 3ittuple: ([1, 2, 3].__iter__(), [11, 22, 33].__iter__(), [111, 222, 333].__iter__())result: (None, None, None)
所以目前来说,其它的很好理解,唯独这个result让人有点懵,搞不懂它是干什么的。不过既然有这个成员,那就说明它肯定有用武之地,而派上用场的地方不用想,肯定是在迭代的时候使用。
static PyObject *
zip_next(zipobject *lz)
{
Py_ssize_t i; // 循环遍变量
Py_ssize_t tuplesize = lz->tuplesize; // 可迭代对象数量
PyObject *result = lz->result; // (None, None, ....)
PyObject *it; // 每一个迭代器
// 代码中体现
PyObject *item;
PyObject *olditem;
// tuplesize == 0, 直接返回
if (tuplesize == 0)
return NULL;
// 如果 result 的引用计数为1, 证明该元组的空间的被申请了
if (Py_REFCNT(result) == 1) {
// 因为它要作为返回值返回, 引用计数加1
Py_INCREF(result);
// 遍历
for (i=0 ; i < tuplesize ; i++) {
// 依次获取每一个迭代器
it = PyTuple_GET_ITEM(lz->ittuple, i);
// 迭代出相应的元素
item = (*Py_TYPE(it)->tp_iternext)(it);
// 如果出现了NULL, 证明迭代结束了, 会直接停止
// 所以会以元素最少的可迭代对象(迭代器)为准
if (item == NULL) {
Py_DECREF(result);
return NULL;
}
// 设置在 result 中, 但是要先获取result中原来的元素, 并将其引用计数减1, 因为元组不再持有对它的引用
olditem = PyTuple_GET_ITEM(result, i);
PyTuple_SET_ITEM(result, i, item);
Py_DECREF(olditem);
}
} else {
// 否则的话同样的逻辑, 只不过需要自己重新手动申请一个tuple
result = PyTuple_New(tuplesize);
if (result == NULL)
return NULL;
// 然后下面的逻辑是类似的
for (i=0 ; i < tuplesize ; i++) {
it = PyTuple_GET_ITEM(lz->ittuple, i);
item = (*Py_TYPE(it)->tp_iternext)(it);
if (item == NULL) {
Py_DECREF(result);
return NULL;
}
PyTuple_SET_ITEM(result, i, item);
}
}
// 返回元组 result
return result;
}所以当我们进行迭代的时候,迭代出来的是一个元组。
z = zip([1, 2, 3], [11, 22, 33])
print(z.__next__()) # (1, 11)
# 即使只有一个可迭代对象, 依旧是一个元组, 因为底层返回的result就是一个元组
z = zip([1, 2, 3])
print(z.__next__()) # (1,)
# 可迭代对象的嵌套也是一样的规律, 直接把里面的列表看成一个标量即可
z = zip([[1, 2, 3], [11, 22, 33]])
print(z.__next__()) # ([1, 2, 3],)最后,zip 也有一个__reduce__ 方法:
z = zip([1, 2, 3], [11, 22, 33])
print(z.__reduce__())
# (<class 'zip'>, (<list_iterator object at 0x0000018D1723B0D0>, <list_iterator object at 0x0000018D1723B040>))
print([tuple(_) for _ in z.__reduce__()[1]]) # [(1, 2, 3), (11, 22, 33)]map、filter 和 列表解析之间的区别
其实在使用 map、filter 的时候,我们完全可以使用列表解析来实现。比如:
lst = [1, 2, 3, 4]
print([str(_) for _ in lst]) # ['1', '2', '3', '4']
print(list(map(str, lst))) # ['1', '2', '3', '4']这两者之间实际上是没有什么太大区别的,都是将 lst 中的元素一个一个迭代出来、然后调用 str 、返回结果。如果非要找出区别话,就是列表解析使用的是 Python 的for循环,而调用list的时候使用的是C中的for循环。从这个角度来说,使用 map 的效率会更高一些。

所以后者的效率稍微更高一些,因为列表解析用的是 Python 的for循环,list(map(func, iter)) 用的是C的for循环。但是注意:如果是下面这种做法的话,会得到相反的结果。

我们看到 map 貌似变慢了,其实原因很简单,后者多了一层匿名函数的调用,所以速度变慢了。
如果列表解析也是函数调用的话:

会发现速度更慢了,当然这种做法完全是吃饱了撑的。之所以说这些,是想说明在同等条件下,list(map) 这种形式是要比列表解析快的。当然在工作中,这两者都是可以使用的,这点效率上的差别其实不用太在意,如果真的到了需要在乎这点差别的时候,那么你应该考虑的是换一门更有效率的静态语言。
filter 和 列表解析之间的差别,也是如此。

对于过滤含有 1000个 False 和 1个True 的元组,它们的结果都是一样的,但是谁的效率更高呢?首先第一种方式 肯定比 第二种方式快,因为第二种方式涉及到函数的调用;但是第三种方式,我们知道它在底层会走单独的分支,所以再加上之前的结论,我们认为第三种方式是最快的。
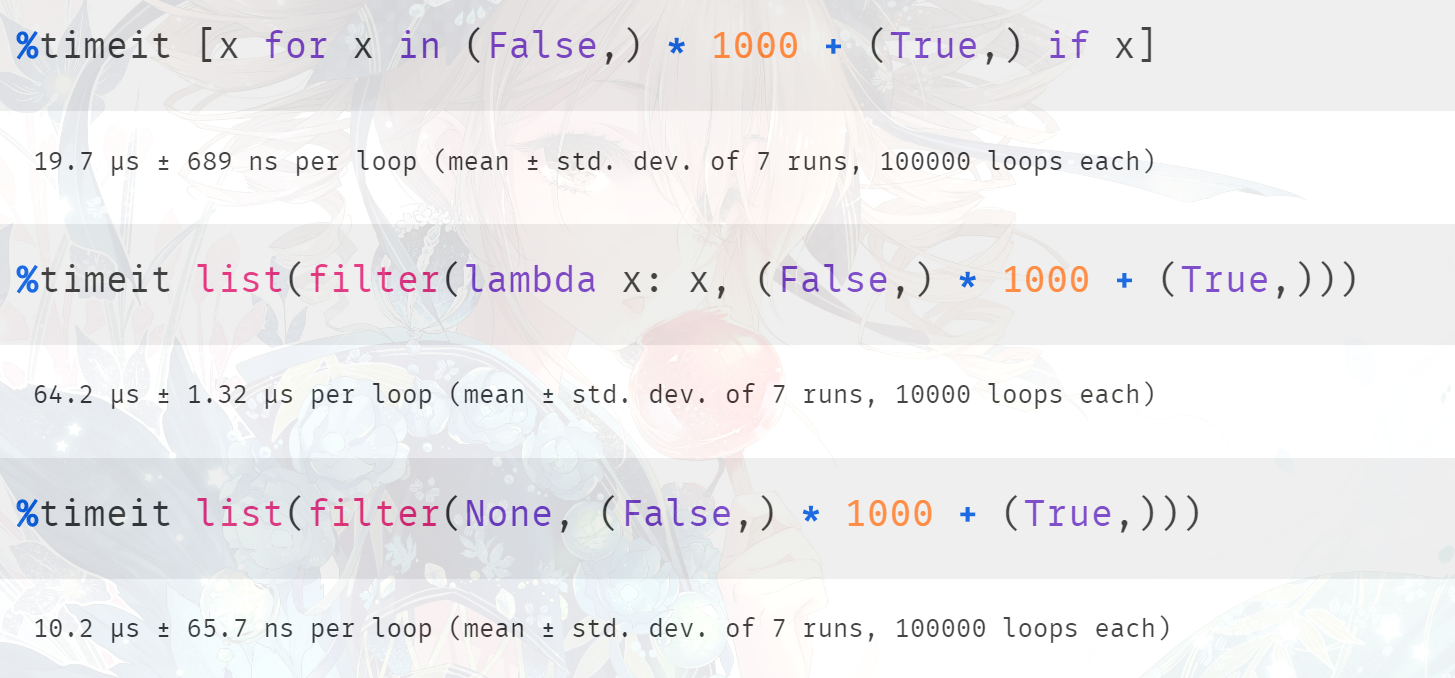
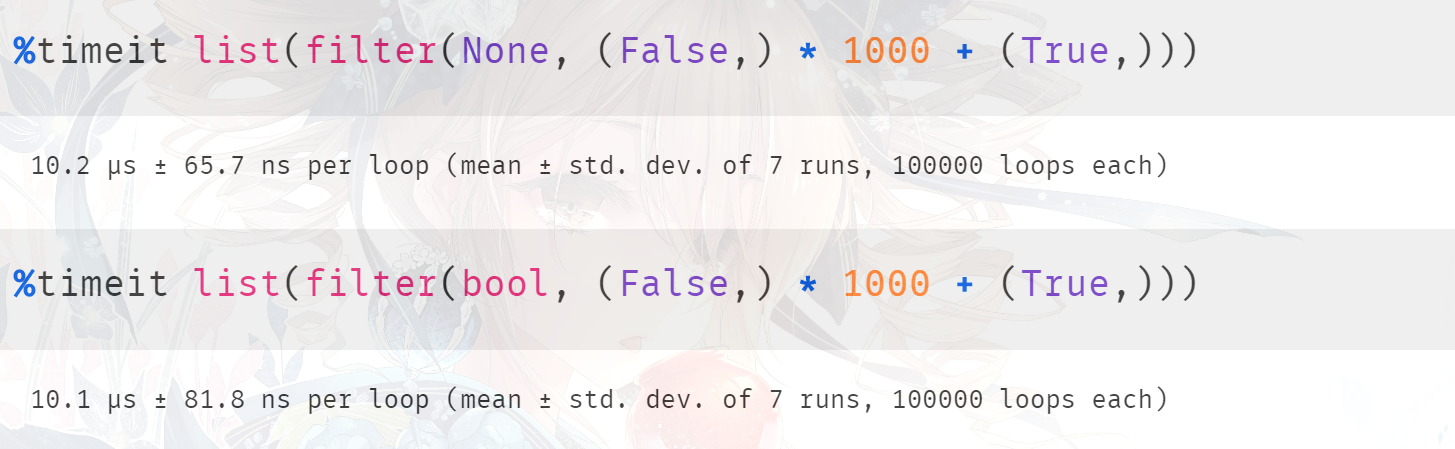
结果也确实是我们分析的这样,当然我们说在底层 None 和 bool 都会走相同的分支,所以这里将 None 换成 bool 也是可以的。虽然 bool 是一个类,但是通过 filter_new 函数我们知道,底层不会进行调用,也是直接使用 PyObject_IsTrue,可以将 None 换成 bool 看看结果如何,应该是差不多的。
总结
所以 map、filter 完全可以使用列表解析替代,如果执行的逻辑比较复杂的话,那么对于 map、filter 而言就要写匿名函数了。但逻辑简单的话,比如:获取为真的元素,完全可以通过list(filter(None, lst))实现,效率更高,因为它走的是相当于是C的循环;但如果获取大于3的元素,那么就需要使用list(filter(lambda x: x > 3, lst))这种形式了,而我们说它的效率是不如列表解析[x for x in lst if x > 3]的,因为前者多了一层函数调用。
但是在工作中,这两种方式都是可以的,使用哪一种就看个人喜好。到此我们发现,如果排除那一点点效率上的差异,那么确实有列表解析式就完全足够了,因为列表解析式可以同时实现 map、filter 的功能,而且表达上也更加地直观。只不过是 map、filter 先出现,然后才有的列表解析式,但是前者依旧被保留了下来。
当然 map、filter 返回的是一个可迭代对象,它不会立即计算,可以节省资源;当然这个功能,我们也可以通过生成器表达式来实现。
map、filter、zip 的底层实现我们就看完了,是不是很简单呢?
另外,如果你得到的结论和我这里的不一致,那么不妨把可迭代对象的元素个数设置的稍微大一些,最终结论和我这里一定是一样的。